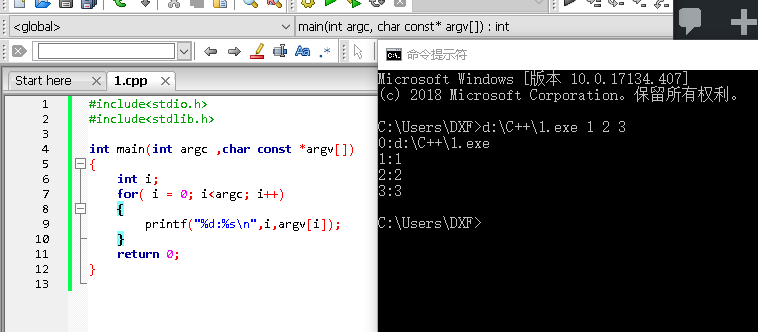
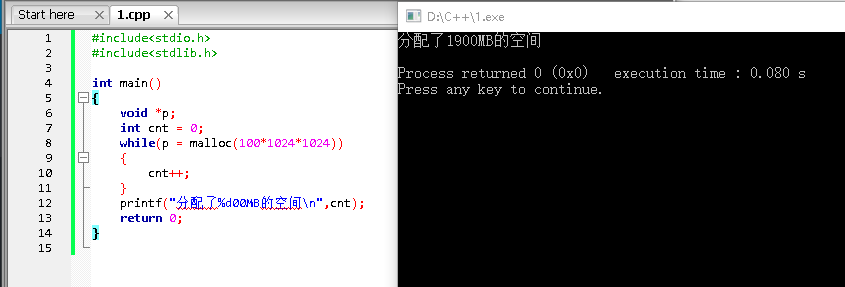
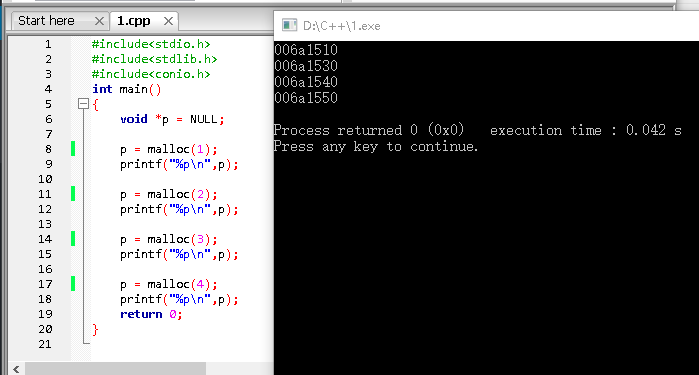
对于字符串,C语言提供了很多函数来帮助我们处理字符串,这些函数都存在于头文件string.h中。
常用的字符串处理函数有:
- strlen
- strcmp
- strcpy
- strcat
- strchr
- strstr
strlen
- size_t strlen(const char *s);
- 返回s的字符串长度
实现代码如下:
#include<stdio.h>
int myStrLen(const char *str)
{
int cnt = 0;
while(str[cnt] != '\0')
{
cnt++;
}
return cnt;
}
int main(int argc ,char const *argv[])
{
char line[] = "Hello World";
printf("strlen=%lu\n",myStrLen(line));
return 0;
}
strcmp
- int strcmp(const char *s1,const char *s2);
- 比较两个字符串,返回:
- 0:s1==s2
- 大于0:s1>s2
- 小于0:s1<s2
数组实现代码如下:
#include<stdio.h>
int myStrCmp(const char *str1,const char *str2)
{
int idx = 0;
while(str1[idx]== str2[idx] && str1[idx]!='\0'){
idx++;
}
return str1[idx]-str2[idx];
}
int main(int argc ,char const *argv[])
{
char s1[] = "Hello World";
char s2[] = "Hello Worle";
printf("%d\n",myStrCmp(s1,s2));
return 0;
}
指针实现代码如下:
#include<stdio.h>
int myStrCmp(const char *str1,const char *str2)
{
int idx = 0;
while(*str1== *str2 && *str1!='\0')
{
str1++;
str2++;
}
return *str1-*str2;
}
int main(int argc ,char const *argv[])
{
char s1[] = "Hello World";
char s2[] = "Hello Worle";
printf("%d\n",myStrCmp(s1,s2));
return 0;
}
strcpy
- char * strcpy(char *restrict dst,const char *restrict src);
- 把src的字符串拷贝到dst
- restrict表明src和dst不重叠(C99)
- 返回dst
复制一个字符串的常用方法
char *dst = (char*)malloc(strlen(src)+1);
strcpy(dst,src);
数组实现代码如下:
#include<stdio.h>
char* myStrCpy(char *dst,char *src)
{
int idx = 0;
while(src[idx] != '\0')
{
dst[idx] = src[idx];
idx++;
}
dst[idx] = '\0';
return dst;
}
int main(int argc ,char const *argv[])
{
char s1[] = "";
char s2[] = "Hello World";
myStrCpy(s1,s2);
printf("%s\n",s1);
return 0;
}
指针实现代码如下:
#include<stdio.h>
char* myStrCpy(char *dst,char *src)
{
while(*src != '\0')
{
*dst = *src;
dst++;
src++;
}
*dst = '\0';
return dst;
}
int main(int argc ,char const *argv[])
{
char s1[] = "";
char s2[] = "Hello World";
myStrCpy(s1,s2);
printf("%s\n",s1);
return 0;
}
strcat
- char *strcat(char *dst,const char *src);
- 把src所指向的字符串(包括“\0”)复制到dest所指向的字符串后面(删除*dest原来末尾的“\0”)。
- 要保证*dest足够长,以容纳被复制进来的*src。*src中原有的字符不变。
- 返回指向dest的指针。
实现代码:
#include<stdio.h>
char* myStrCat(char *dst,const char *src)
{
char *temp = dst;
while(*dst!='\0')
{
dst++;
}
while(*src!='\0')
{
*dst = *src;
dst++;
src++;
}
*dst = '\0';
return temp;
}
int main(int argc ,char const *argv[])
{
char s1[] = "Hello ";
char s2[] = "World";
myStrCat(s1,s2);
printf("%s\n",s1);
return 0;
}
strchr
- char* strchr(const char *s , char c);
- 返回首次出现字符c的位置的指针,如果字符串s中不存在字符c则返回NULL。
实现代码:
#include<stdio.h>
char* myStrChr(char *s,char c)
{
while(*s!='\0' && *s!= c)
{
s++;
}
return *s==c ? s+1 : NULL;
}
int main(int argc ,char const *argv[])
{
char s1[] = "Hello World";
char s2 = 'W';
char *ptr = myStrChr(s1,s2);
printf("%s\n",ptr);
return 0;
}
strstr
- char* strstr(char *str,const char *str2);
- str1:被查找目标
- str2:要查找目标
- 返回值:若str2是str1的子串,则返回str2在str1的首次出现的地址;如果str2不是str1的子串,则返回NULL。
实现代码:
#include<stdio.h>
char* myStrStr(char *s1,const char *s2)
{
bool flag = false;
char *temp1 = s1;
char *temp2 = (char*)s2;
while(*s1 != '\0' )
{
if(*s2 == '\0')
{
flag = true;
break;
}
else if(*s1==*s2)
{
s1++;
s2++;
}
else
{
s1++;
s1 = ++temp1;
s2 = temp2;
}
}
if(flag)
{
return temp1;
}
else return NULL;
}
int main(int argc ,char const *argv[])
{
char s1[] = "Hello World";
char s2[] = "Wor";
char *ptr = myStrStr(s1,s2);
printf("%s\n",ptr);
return 0;
}