C++的空类是指设计时不包含任何数据成员和成员函数的类。
实际上,对于一个空类,系统会自动添加以下默认的成员函数:
1.默认构造函数
2.默认拷贝构造函数
3.默认析构函数
4.赋值“=”运算符
5.取地址运算符
6.取地址运算符const
对于一个空类A,sizeof(A)的值为1,这是因为实例化的原因,空类同样可以被实例化,每个实例在内存中都应该有唯一的地址,为了达到这个目的,编译器会给一个空类插入一个字节,这样空类在实例化后在内存中得到唯一的地址,所以空类所占的内存大小是1个字节。
C++的空类是指设计时不包含任何数据成员和成员函数的类。
实际上,对于一个空类,系统会自动添加以下默认的成员函数:
1.默认构造函数
2.默认拷贝构造函数
3.默认析构函数
4.赋值“=”运算符
5.取地址运算符
6.取地址运算符const
对于一个空类A,sizeof(A)的值为1,这是因为实例化的原因,空类同样可以被实例化,每个实例在内存中都应该有唯一的地址,为了达到这个目的,编译器会给一个空类插入一个字节,这样空类在实例化后在内存中得到唯一的地址,所以空类所占的内存大小是1个字节。
在C++中,类对象的存储空间分配方式如下:
(1)一个类对象的分配空间中仅包含所有非静态数据成员,并按照这些数据成员定义的顺序存放。
(2)一个类对象的大小为其所有非静态数据成员的类型大小之和,普通成员函数与sizeof是没有关系的。当类中有一个或者多个虚函数时,由于要维护虚函数表,所以有一个虚函数表指针,另外当存在虚继承时还需要一个指向虚基类的指针,每个指针占用一个地址大小的内存空间,即4个字节。
(3)类对象中的各个数据成员分配内存时也遵守内存对齐规则。内存对齐规则请看:内存对齐
在了解了对象的存储结构后,可以采用取指定地址中值的方式访问对象的私有数据成员,如下程序所示:
#include<iostream>
using namespace std;
class A{
private:
int x;
int y;
public:
A(int i,int j){
x = i;
y = j;
}
};
int main()
{
A a(1,3);
cout<<"a.x="<<*((int *)(&a))<<endl;
cout<<"a.y="<<*((int *)(&a)+1)<<endl;
}
输出为:
a.x=1 a.y=3 Program ended with exit code: 0
assert宏(在assert.h头文件中定义)用于测试表达式的值,如果表达式的值为假,则assert输出错误信息,并调用函数abort()以结束程序。这是测试某个变量是否具有正确值的有用的调试工具例如以下语句就是一个断言:
assert(x<10);
当在程序中遇到这个语句时,如果x的值大于或等于10,则将打印包含行号和文件名的错误信息,而且程序终止。然后程序将在这个代码区域内查找错误。
void *memcpy(void *&pvTo, const void *pvFrom, size_t size) {
char *pbTo = (char*)pvTo;
char *pbFrom = (char*)pvFrom;
assert((pvTo != NULL) && (pvFrom != NULL));
//使用断言检查输入指针的有效性
assert(pbTo >= pbFrom + size || pbFrom >= pbTo + size);
//使用断言检查两个指针指向的内存区域是否重叠
while(size -- > 0 )
*pbTo++ = *pbFrom++ ;
}
可以通过定义 NDEBUG 来关闭 assert,但是需要在源代码的开头,include <assert.h> 之前。
要求:
排序算法可以说是一项基本功,解决实际问题中经常遇到,针对实际数据的特点选择合适的排序算法可以使程序获得更高的效率,有时候排序的稳定性还是实际问题中必须考虑的。
需求分析
我们的程序需要实现几个模块,其中包括
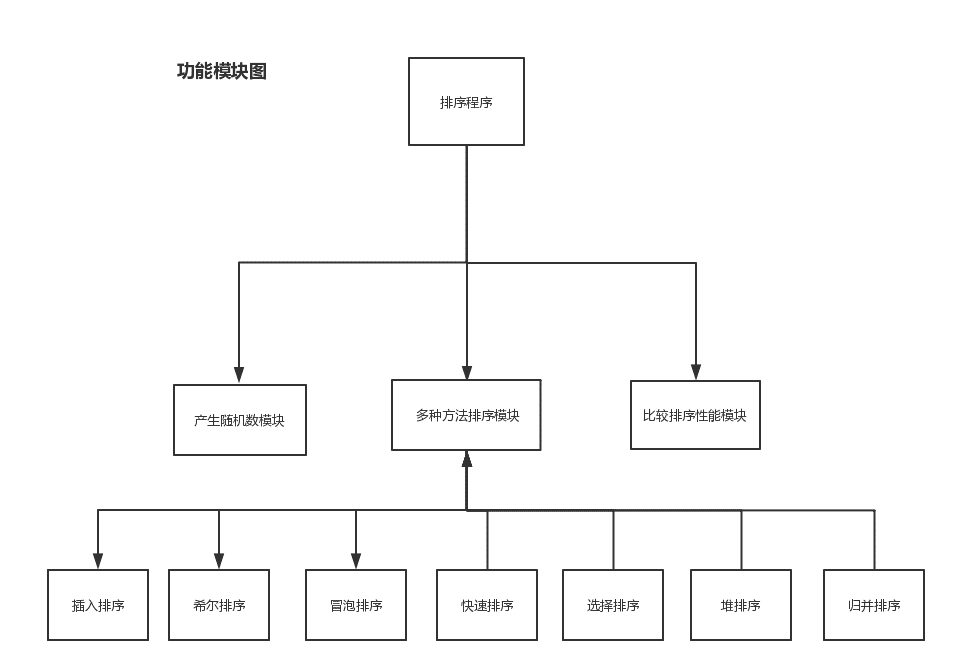
产生随机数模块可以通过C++的rand()函数随机生成伪随机数,并将这20000个随机数存在一个名为number.txt的文件中。
然后在程序中实现插入排序、希尔排序、冒泡排序、快速排序、选择排序、堆排序、归并排序等排序方法以完成多种方法排序模块。
然后通过执行不同的排序算法所花费的时间进行比较,得出最快的两种方法,并得出以上排序算法的性能排名。
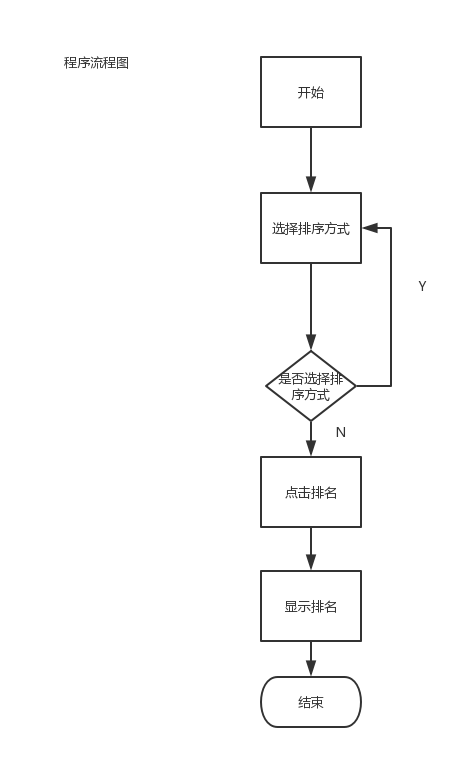
程序流程图:
系统设计
开发环境:
操作系统:Microsoft Windows 10 64位
IDE:CodeBlocks 32位
编译器:GNU GCC Compiler
编程语言:C++
图形库:ACLLib
数据结构:
本程序使用了顺序表来存储所有的数据,并基于顺序表的结构进行排序。
同时,本程序使用了ACLLib图形库画出了简单的图形界面,使我们的性能对比更加直观。
函数调用关系图:

排序算法伪代码:
插入排序:
for i←2 to n
x←A[i]
j←i-1
while(j>0) and (A[j]>x)
A[j+1]←A[j]
j←j-1
end while
A[j+1]←x
end for
希尔排序:
input: an array a of length n with array elements numbered 0 to n − 1
inc ← round(n/2)
while inc > 0 do:
for i = inc .. n − 1 do:
temp ← a[i]
j ← i
while j ≥ inc and a[j − inc] > temp do:
a[j] ← a[j − inc]
j ← j − inc
a[j] ← temp
inc ← round(inc / 2.2)
冒泡排序:
BubbleSort(input ele[],input length)
for i <- 1 to length step 1
for j <- i+1 to 0 step -1
if ele[j] < ele [j – 1]
swap (ele[j],ele[j – 1])
end if
end
end
快速排序:
if low<high then
SPLIT(A[low…high],w) //w为A[low]的新位置
quicksort(A,low,w-1)
quicksort(A,w+1,high)
end if
选择排序:
for i←1 to n-1
k←i //设立标志位
for j←i+1 to n //查找第i小的元素
if A[j]<A[k] then k←j
end for
if k≠i then 交换A[i]与A[k]
end for
堆排序:
1.下标计算[为与程序对应,下标从0开始]
Parent(i)://为了伪代码描述方便
returni/2
Left(i):
return2*i+1
Right(i):
return2*i+2
2.使下标i元素为根的的子树成为最大堆
MAX_HEAPIFY(A,i):
l<——Left(i)
r<——Right(i)
ifl<length(A)andA[l]>A[i]
thenlargest<——l
elselargest<——i
ifr<length(A)andA[r]>A[largest]
thenlargest<——r
iflargest!=i
thenexchangeA[i]<——>A[largest]//到这里完成了一层下降
MAX_HEAPIFY(A,largest)//这里是递归的让当前元素下降到最低位置
3.最大堆的建立,将数组A编译成一个最大堆
BUILD_MAX_HEAP(A):
heapsize[A]<——length[A]
fori<——length[A]/2+1 to0
MAX_HEAPIFY(A,i)//堆排序的开始首先要构造大顶堆,这里就是对内层节点进行逐级下沉(小元素)
4.堆排序
HEAP_SORT(A):
BUILD_MAX_HEAP(A)
fori<——length[A]-1to1//这里能够保证堆大小和数组大小的关系,堆在每一次置换后都减一
doexchangeA[1]<——> A[i]
length[A]<——length[A]-1
MAX_HEAPIFY(A,0)//对交换后的元素下沉
归并排序:
mergesort(A,1,n)
if low<high then
mid←⌊(low+high)/2⌋
mergesort(A,low,mid)
mergesort(A,mid+1,high)
MERGE(A,low,mid,high)
end if
MERGE()
//B[p…r]是个辅助数组
s←p;t←q+1;k←p
while s≤q and t≤r
if A[s]≤A[t] then
B[k]←A[s]
s←s+1
else
B[k]←A[t]
t←t+1
end if
k←k+1
end while
if s=q+1 then B[k…r]←A[t…r]
else B[k…r]←A[s…q]
end if
A[p…r]←B[p…r]
系统实现
函数功能:
(1)void adjust(int arr[], int len, int index) // 递归方式构建大根堆(len是arr的长度,index是第一个非叶子节点的下标)
(2)void bubbleSort(int nums[],int n) //冒泡排序算法
(3)bool comp(const mysort &a,const mysort &b)//结构体的排序函数
(4)string doubleToString(double num)//double类型转string类型函数
(5)void heapSort(int nums[],int n) //堆排序算法
(6)void insertSort(int nums[],int n) //插入排序算法
(7)void makeRandNumber()//生成20000个随机数放在项目目录的number.txt下
(8)void Merge(int A[], int start, int mid, int step, int n)//归并排序算法
(9)void mergeSort(int nums[],int n) //递归进行归并排序
(10)void mouseListener(int x , int y ,int button ,int event){//监听函数,用来判断鼠标点击
(11)void quickSort(int b, int e, int a[])//快速排序算法
(12)void readNums(int nums[]) //读取文件中的数字到数组中
(13)void selectionSort(int nums[],int n) //选择排序算法
(14)int Setup()//ACLLib图形库进入Win32程序的入口函数
(15)void shellSort(int nums[],int n) //希尔排序算法
(16)void showIndex()//画出界面的首页
算法:
思想:
每次选择一个元素K插入到之前已排好序的部分A[1…i]中,插入过程中K依次由后向前与A[1…i]中的元素进行比较。若发现发现A[x]>=K,则将K插入到A[x]的后面,插入前需要移动元素。
时间复杂度:
最好的情况下:正序有序(从小到大),这样只需要比较n次,不需要移动。因此时间复杂度为O(n)
最坏的情况下:逆序有序,这样每一个元素就需要比较n次,共有n个元素,因此实际复杂度为O(n2)
平均情况下:O(n2)
稳定性:
理解性记忆比死记硬背要好。因此,我们来分析下。稳定性,就是有两个相同的元素,排序先后的相对位置是否变化,主要用在排序时有多个排序规则的情况下。在插入排序中,K1是已排序部分中的元素,当K2和K1比较时,直接插到K1的后面,没有必要插到K1的前面,因为这样做还需要移动。因此,插入排序是稳定的。
实现代码:
void insertSort(int nums[],int n) //插入排序
{
//从第二个元素开始,加入第一个元素是已排序数组
for (int i = 1; i < n; i++)
{
//待插入元素 nums[i]
if (nums[i] < nums[i – 1])
{
int wait = nums[i];
int j = i;
while (j > 0 && nums[j – 1] > wait)
{
//从后往前遍历已排序数组,若待插入元素小于遍历的元素,则遍历元素向后挪位置
nums[j] = nums[j – 1];
j–;
}
nums[j] = wait;
}
}
}
思想:
希尔排序也是一种插入排序方法,实际上是一种分组插入方法。先取定一个小于n的整数d1作为第一个增量,把表的全部记录分成d1个组,所有距离为d1的倍数的记录放在同一个组中,在各组内进行直接插入排序;然后,取第二个增量d2(<d1),重复上述的分组和排序,直至所取的增量dt=1(dt<dt-1<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
时间复杂度:
最好情况:由于希尔排序的好坏和步长d的选择有很多关系,因此,目前还没有得出最好的步长如何选择(现在有些比较好的选择了,但不确定是否是最好的)。所以,不知道最好的情况下的算法时间复杂度。
最坏情况下:O(n*logn),最坏的情况下和平均情况下差不多。
平均情况下:O(N*logn),实际约为O(n(1.3—2))。
稳定性:
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
实现代码:
void shellSort(int nums[],int n) //希尔排序
{
int i, j;
int increment = n;
do
{
increment = increment / 3 +1;
for (i = increment ; i <= n – 1; i++)
{
if (nums[i] < nums[i – increment])
{
int tmp;
tmp = nums[i];
for (j = i – increment; j >= 0 && tmp < nums[j]; j -= increment)
nums[j + increment] = nums[j];
nums[j + increment] = tmp;
}
}
}
while (increment > 1);
}
思想:
通过无序区中相邻记录关键字间的比较和位置的交换,使关键字最小的记录如气泡一般逐渐往上“漂浮”直至“水面”。
时间复杂度:
最好情况下:正序有序,则只需要比较n次。故,为O(n)。
最坏情况下: 逆序有序,则需要比较(n-1)+(n-2)+……+1,故,为O(N*N)。
稳定性:
排序过程中只交换相邻两个元素的位置。因此,当两个数相等时,是没必要交换两个数的位置的。所以,它们的相对位置并没有改变,冒泡排序算法是稳定的。
实现代码:
void bubbleSort(int nums[],int n) //冒泡排序
{
for(int i = 0; i<n-1; i++)
{
for(int j = i+1; j<n; j++)
{
if(nums[i]>nums[j])
{
swap(nums[i],nums[j]);
}
}
}
}
思想:
它是由冒泡排序改进而来的。在待排序的n个记录中任取一个记录(通常取第一个记录),把该记录放入适当位置后,数据序列被此记录划分成两部分。所有关键字比该记录关键字小的记录放置在前一部分,所有比它大的记录放置在后一部分,并把该记录排在这两部分的中间(称为该记录归位),这个过程称作一趟快速排序。
时间复杂度:
最好的情况下:因为每次都将序列分为两个部分(一般二分都复杂度都和logN相关),故为 O(N*logN)。
最坏的情况下:基本有序时,退化为冒泡排序,几乎要比较N*N次,故为O(N*N)。
稳定性:
由于每次都需要和中轴元素交换,因此原来的顺序就可能被打乱。如序列为 5 3 3 4 3 8 9 10 11会将3的顺序打乱。所以说,快速排序是不稳定的。
实现代码:
void quickSort(int b, int e, int a[])
{
int i = b, j = e; //i是数组的头,j是数组的尾
int x = a[(b + e) / 2]; //选取数组的中间元素作为划分的基准
while (i<j)
{
while (a[i]<x) i++;
while (a[j]>x) j–;
if (i <= j)
std::swap(a[i++], a[j–]);
}
if (i<e)
quickSort(i, e, a);
if (j>b)
quickSort(b, j, a);
}
思想:
首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。以此类推,直到所有元素均排序完毕。具体做法是:选择最小的元素与未排序部分的首部交换,使得序列的前面为有序。
时间复杂度:
最好情况下:交换0次,但是每次都要找到最小的元素,因此大约必须遍历N*N次,因此为O(N*N),减少了交换次数。
最坏情况下,平均情况下:O(N*N)。
稳定性:
由于每次都是选取未排序序列A中的最小元素x与A中的第一个元素交换,因此跨距离了,很可能破坏了元素间的相对位置,因此选择排序是不稳定的。
实现代码:
void selectionSort(int nums[],int n) //选择排序
{
int i, j, minn;
for (i = 0; i < n – 1; i++)
{
minn = i; //记录最小值的下标,初始化为i
for (j=i+1; j<=n-1; j++)
{
if (nums[j] < nums[minn])
minn = j; //通过不断地比较,得到最小值的下标
}
swap(nums[i], nums[minn]);
}
}
思想:
利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或者最小)的记录。也就是说,以最小堆为例,根节点为最小元素,较大的节点偏向于分布在堆底附近。
时间复杂度:
最坏情况下,接近于最差情况下:O(N*logN),因此它是一种效果不错的排序算法。
稳定性:
堆排序需要不断地调整堆,因此它是一种不稳定的排序。
实现代码:
// 递归方式构建大根堆(len是arr的长度,index是第一个非叶子节点的下标)
void adjust(int arr[], int len, int index)
{
int left = 2*index + 1; // index的左子节点
int right = 2*index + 2;// index的右子节点
int maxIdx = index;
if(left<len && arr[left] > arr[maxIdx]) maxIdx = left;
if(right<len && arr[right] > arr[maxIdx]) maxIdx = right;
if(maxIdx != index)
{
swap(arr[maxIdx], arr[index]);
adjust(arr, len, maxIdx);
}
}
void heapSort(int nums[],int n) //堆排序
{
// 构建大根堆(从最后一个非叶子节点向上)
for(int i=n/2 – 1; i >= 0; i–)
{
adjust(nums, n, i);
}
// 调整大根堆
for(int i = n – 1; i >= 1; i–)
{
swap(nums[0], nums[i]); // 将当前最大的放置到数组末尾
adjust(nums, i, 0); // 将未完成排序的部分继续进行堆排序
}
}
思想:
多次将两个或两个以上的有序表合并成一个新的有序表。
时间复杂度:
最好的情况下:一趟归并需要n次,总共需要logN次,因此为O(N*logN) 。
最坏的情况下,接近于平均情况下,为O(N*logN) 。
说明:对长度为n的文件,需进行logN 趟二路归并,每趟归并的时间为O(n),故其时间复杂度无论是在最好情况下还是在最坏情况下均是O(nlgn)。
稳定性:
归并排序最大的特色就是它是一种稳定的排序算法。归并过程中是不会改变元素的相对位置的。
实现代码:
void Merge(int A[], int start, int mid, int step, int n)
{
int rightLen = 0;
if (mid + step > n)
{
rightLen = n – mid;
}
else
{
rightLen = step;
}
//申请空间存放临时结果
int *tempArray = new int[step + rightLen]();
int i = 0, j = 0, k = 0;
while (i < step && j < rightLen)
{
if (A[start + i] < A[mid + j])
{
tempArray[k++] = A[start + i];
i++;
}
else
{
tempArray[k++] = A[mid + j];
j++;
}
}
//如果左边没有归并完,那么直接将剩余的元素复制到tempArray的后面
if (j == rightLen)
{
memcpy(tempArray + i + j, A + start + i, (step – i) * sizeof(int));
}
//如果右边没有归并完,那么直接将剩余的元素复制到tempArray的后面
else if (i == step)
{
memcpy(tempArray + i + j, A + mid + j, (rightLen – j) * sizeof(int));
}
//将临时数组中排好序的内容复制回原数组
memcpy(A + start, tempArray, (step + rightLen) * sizeof(int));
delete[] tempArray;
}
void mergeSort(int nums[],int n) //归并排序
{
for (int step = 1; step < n; step *= 2)
{
for (int i = 0; i < n – step; i += 2*step)
{
Merge(nums ,i, i+step, step, n);
}
}
}
最后,排序其实是有改进方法的,最近研究了一下。
快速排序主要有以下几种改进方法:
快速排序基本思路:找到一个标定点,左边的元素小于标定点,右边元素大于标定点,然后再对左右区间递归快速排序。
改进1:如果数组近乎有序,标定点的选择会影响快速排序的性能,如果每次都选择最小值作为标定点,快速排序时间复杂度会退化为O(N*N),因此需要随机化标定点元素。
改进2:如果数组有大量相同元素,上面的做法会将相同元素分到大于v的区间,会造成两个子区间元素不平衡,所以需要将相等元素平衡地分入两个区间。
改进3:可以改成三路快速排序算法。
当然,在我们程序中排名最慢的冒泡排序也是可以优化的,我们都知道,当一个序列已经有序的情况下,冒泡排序往往会做很多不必要的重复的比较,在此基础上我们能够优化一下。
优化:设置一个标志符flag,flag初始值是0,如果在一趟遍历中有出现元素交换的情况,那就把flag置为1。一趟冒泡结束后,检查flag的值。如果flag依旧是0,那这一趟就没有元素交换位置,说明数组已经有序,循环结束。
用户手册
首先运行我们的程序,界面如下:
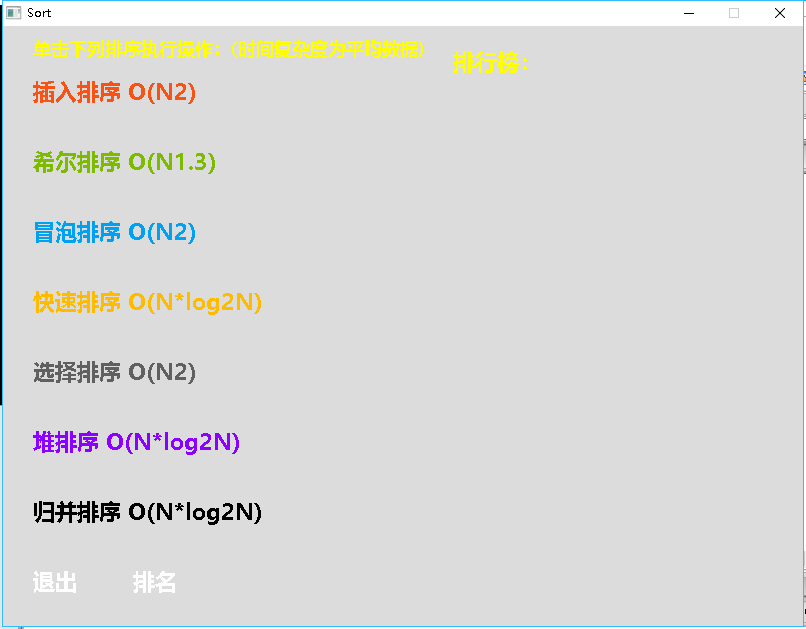
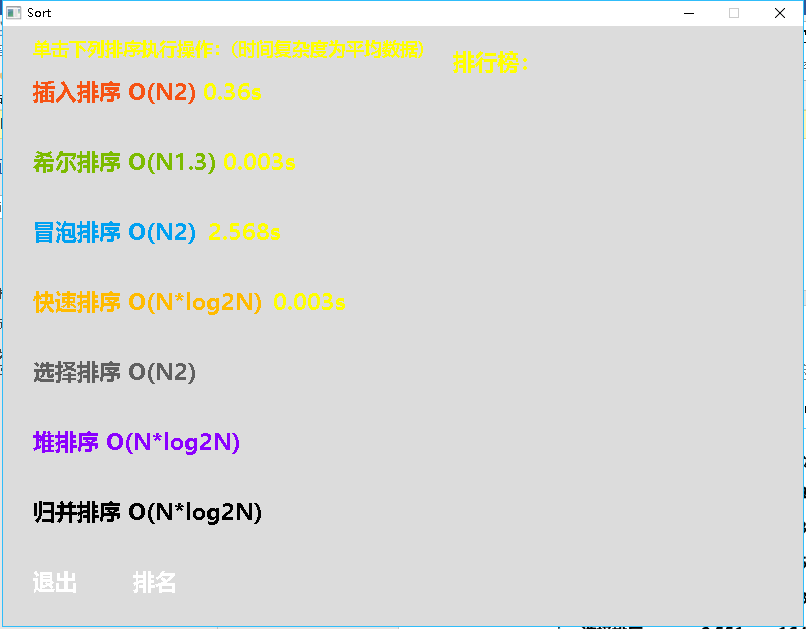
分别用鼠标左键单击插入排序、希尔排序、冒泡排序、快速排序、选择排序、堆排序、归并排序,界面会显示出我们执行相应的算法所花费的时间,如图所示:
与此同时,我们的项目目录下会多出一些文本文件,这些文本文件分别是各种排序算法的结果,我们用文本将结果保存下来,如图所示:
最后,我们点击排名,即可看到各种算法的性能比较排名,如图所示:

排序是软件设计中最常用的运算之一,有多种不同的算法,每种算法各有其特定性和最合适的适用范围。因此,了解这些特性对于实际应用时选择最恰当算法是软件设计中的重要技术。通过本次课程设计,我体会到了各种算法的性能特点,包括时间性能、空间性能以及排序的稳定性。同时,通过实验的方法来分析算法的各种性能是计算机科学与技术领域重要的手段,是研究各类问题求解的新算法所必需的技术,应引起足够的重视,可以看出在数据规模达到一定数目时,我们的冒泡排序算法相对于其他算法所花费的时间越来越多,由此可见算法的性能十分重要。经过测试我们发现在大部分情况下快速排序的效率都是极其高的,但当测试的数据为有序的时候,快排的效率便会降低,并且有可能造成栈溢出等问题。
当然,这里提一下我对排序算法的稳定性的理解,首先,排序算法的稳定性大家应该都知道,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。在简单形式化一下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。其次,说一下稳定性的好处。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。另外,如果排序算法稳定,对基于比较的排序算法而言,元素交换的次数可能会少一些。
最后,在这次课程设计中,我简单的学习了一下图形化编程,受益匪浅,程序不再由黑色的命令行框框组成,而是有趣的图形化界面,增加了我对于编程的兴趣,最后,我们的排序算法还有一些可以优化的地方,我会慢慢学习改进这些排序算法。
在这里我们研究学习的全部都是内部排序,那么外部排序是否也类似呢?在程序的世界里,我们往往在做一些分而治之的事情,通过对内部排序的初步学习和认识,我对外部排序也产生了浓烈的兴趣。
学习和生活中有好多地方都设计排序的问题,学好排序的相关知识很有用。
设计任务:矩阵A中的元素若满足:A[i,j]是第i行中值最小的元素,且又是第j列中值最大的元素,则称元素A[i,j]为该矩阵的一个马鞍点。求出m*n矩阵的所有马鞍点。
要求:使用二维数组、堆分配数组、三元组、十字链表完成上述操作并比较效率。
用不同的存储结构实现寻找m*n的矩阵中的马鞍点的算法。
鞍点(Saddle point)在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点。在泛函中,既不是极大值点也不是极小值点的临界点,叫做鞍点。在矩阵中,一个数在所在行中是最大值,在所在列中是最小值,则被称为鞍点。在物理上要广泛一些,指在一个方向是极大值,另一个方向是极小值的点。所以,寻找马鞍点的算法研究是十分有必要的。
3.1需求分析
该程序主要功能是在一个m*n的矩阵中寻找马鞍点,如果马鞍点存在,则输入该马鞍点的位置信息以及该点的值;如果马鞍点不存在,则输出“没有马鞍点”的提示信息。
程序流程图:

输入形式:
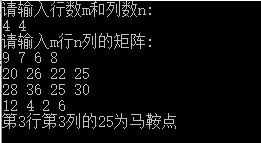
首先输入两个数字,代表矩阵的行数m和列数n。
然后输入m行n列的矩阵。
输出形式:如果马鞍点存在,则输出马鞍点的位置和值,否则输出“没有马鞍点”。
测试样例1:
输入:
4 4
9 7 6 8
20 26 22 25
28 36 25 30
12 4 2 6
输出:
第3行第3列的25为马鞍点
测试样例2:
输入:
5 5
9 5 3 4 8
8 4 5 1 7
5 4 7 2 3
5 8 6 2 1
4 5 7 6 9
输出:
没有马鞍点
3.2系统实现
通过O(n2)时间复杂度的对数组的遍历,寻找出数组中每一行的最小的数字,并存储在数组minn中,寻找出数组中每一列的最大的数字,并存储在数组maxx中,如果minn和maxx数组中存在相同的数则说明该数为该矩阵的马鞍点。
3.3用户手册
此时输入两个数字,代表行和列

此时输入我们的2行2列的矩阵


3.4测试
测试样例1:
测试样例2:

3.5效率比较
下面四种方法的时间复杂度均为O(n2)。
二维数组法:定义方便,但不能灵活的控制内存空间。
堆分配数组法:能灵活的控制内存空间,能自由的控制数组的生存时间。
三元组法:在该程序中代码较为复杂,且花费了更多的空间。
十字链表法:在稀疏矩阵的时候能够省下较多的存储空间,但代码较为复杂。
二维数组法代码:
#include<iostream>
#include<cstring>
using namespace std;
int main()
{
int m ,n;
bool flag = false;
cout<<"请输入行数m和列数n:"<<endl;
cin>>m>>n;
cout<<"请输入m行n列的矩阵:"<<endl;
flag = false;
int minn[n+1];
int maxx[m+1];
memset(minn,0,sizeof(minn));//把数组置为0
memset(maxx,0,sizeof(maxx));//把数组置为0
int a[m+1][n+1];
for(int i = 0; i<m; i++)
{
for(int j = 0; j<n; j++)
{
cin>>a[i][j];
}
}
for(int i=0; i<m; i++) //求出每行最小数,存在minn数组中
{
minn[i]=a[i][0];
for(int j=1; j<n; j++)
if(minn[i]>a[i][j])
minn[i]=a[i][j];
}
for(int j=0; j<n; j++) //求出每列最大数,存在maxx数组中
{
maxx[j]=a[0][j];
for(int i=1; i<m; i++)
if(maxx[j]<a[i][j])
maxx[j]=a[i][j];
}
for(int i=0; i<m; i++)
{
for(int j=0; j<n; j++)
{
if(minn[i]==maxx[j])//找到马鞍点
{
cout<<"第"<<i+1<<"行第"<<j+1<<"列的"<<a[i][j]<<"为马鞍点"<<endl;//i+1 j+1原因:第几行第几列从1开始,而数组从0开始
flag = true;
}
}
}
if(flag == false)
{
cout<<"没有马鞍点"<<endl;
}
}
堆分配数组法代码:
#include<iostream>
#include<cstring>
#include<stdlib.h>
using namespace std;
int main()
{
int m ,n;
bool flag = false;
cout<<"请输入行数m和列数n:"<<endl;
cin>>m>>n;
cout<<"请输入m行n列的矩阵:"<<endl;
flag = false;
int *minn = (int*)malloc(n*sizeof(int));
int *maxx = (int*)malloc(m*sizeof(int));
memset(minn,0,sizeof(minn));//把数组置为0
memset(maxx,0,sizeof(maxx));//把数组置为0
int **a=(int**)malloc(sizeof(int*)*m);
for(int i=0; i<m; i++)
{
a[i]=(int*)malloc(sizeof(int)*n);
}
for(int i = 0; i<m; i++)
{
for(int j = 0; j<n; j++)
{
cin>>a[i][j];
}
}
for(int i=0; i<m; i++) //求出每行最小数,存在minn数组中
{
minn[i]=a[i][0];
for(int j=1; j<n; j++)
if(minn[i]>a[i][j])
minn[i]=a[i][j];
}
for(int j=0; j<n; j++) //求出每列最大数,存在maxx数组中
{
maxx[j]=a[0][j];
for(int i=1; i<m; i++)
if(maxx[j]<a[i][j])
maxx[j]=a[i][j];
}
for(int i=0; i<m; i++)
{
for(int j=0; j<n; j++)
{
if(minn[i]==maxx[j])//找到马鞍点
{
cout<<"第"<<i+1<<"行第"<<j+1<<"列的"<<a[i][j]<<"为马鞍点"<<endl;//i+1 j+1原因:第几行第几列从1开始,而数组从0开始
flag = true;
}
}
}
if(flag == false)
{
cout<<"没有马鞍点"<<endl;
}
free(minn);
free(maxx);
free(a);
}
三元组法代码:
#include<iostream>
#include<cstring>
#include<stdlib.h>
using namespace std;
typedef struct
{
int i,j,e;
} Triple; //数据类型 三元组
typedef struct
{
Triple *base; //矩阵基址
int MatrixSize; //当前的矩阵大小
int mu,nu; //当前长度
} Matrix; //矩阵抽象数据类型
int main()
{
while(1)
{
bool flag = false;
int m,n,p=0;
int value;
Matrix a;
cout<<"请输入行数m和列数n:"<<endl;
cin>>a.mu>>a.nu;
a.base=(Triple *)malloc(a.mu*a.nu*sizeof(Triple));
cout<<"请输入m行n列的矩阵:"<<endl;
flag = false;
int minn[a.mu];
int maxx[a.nu];
memset(minn,0,sizeof(minn));//把数组置为0
memset(maxx,0,sizeof(maxx));//把数组置为0
for(int i = 0; i<a.mu; i++)
{
for(int j = 0; j<a.nu; j++)
{
cin>>a.base[p].e;
a.base[p].i = i;
a.base[p].j = j;
p++;
}
}
p = 0;
int row,col;
int q=0,order=0;
for(row=1; row<=a.mu; row++)
{
p=(row-1)*a.nu;//行首元素的下标
minn[row]=a.base[p].e; //令每行的第一个元素为最小值
for(col=2; col<=a.nu; col++) //从每行的第二个元素开始遍历
{
p++; //同一行元素存储位置连续,下标下移
if(minn[row]>a.base[p].e)
minn[row]=a.base[p].e;
}
}
for(col=1; col<=a.nu; col++)
{
maxx[col]=a.base[col-1].e;//令每列的第一个元素为最大值
for(row=2; row<=a.mu; row++) //从每列的第二个元素开始遍历
{
q=(row-1)*a.nu+col-1;//col列的第row个元素的下标,完成同一列元素的依次遍历
if(maxx[col]<a.base[q].e)
maxx[col]=a.base[q].e;
}
}
for(p=1; p<=a.mu; p++)
{
for(q=1; q<=a.nu; q++)
{
if(minn[p]==maxx[q])
{
cout<<"第"<<p<<"行第"<<q<<"列的"<<minn[p]<<"为马鞍点"<<endl;
flag = true;
}
}
}
if(flag == false)
{
cout<<"没有马鞍点"<<endl;
}
}
}
十字链表法代码:
#include<stdio.h>
#include<stdlib.h>
#include<iostream>
#include<limits.h>
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define OVERFLOW -2
#define INFEASIBLE -1
using namespace std;
typedef int ElemType;
typedef struct OLNode
{
int i,j;
ElemType e;
struct OLNode *right, *down;
} OLNode, *OLink;
typedef struct
{
OLink *rhead, *chead;
int mu,nu,tu;
} CrossList;
int CreateSMatrix_OL(CrossList *M)
{
if(M) free(M);
int m,n,t=0;
printf("请输入行数m和列数n:\n");
scanf("%d%d",&m,&n);
printf("请输入m行n列的矩阵:\n");
M->mu=m;
M->nu=n;
if(!(M->rhead=(OLink *)malloc((m+1)*sizeof(OLink)))) return ERROR;
if(!(M->chead=(OLink *)malloc((n+1)*sizeof(OLink)))) return ERROR;
int a,b;
for (a=1; a<=m; a++) M->rhead[a]=NULL;
for (b=1; b<=n; b++) M->chead[b]=NULL;
int i,j,e;
for(i=1; i<=m; i++)
{
for(j=1; j<=n; j++)
{
scanf("%d",&e);
if(e!=0)
{
t++;
OLNode *p,*q;
if(!(p=(OLNode *)malloc(sizeof(OLNode)))) return ERROR;
p->i=i;
p->j=j;
p->e=e;
p->down=NULL;
p->right=NULL;
if(M->rhead[i]==NULL||M->rhead[i]->j>j)
{
p->right=M->rhead[i];
M->rhead[i]=p;
}
else
{
for(q=M->rhead[i]; (q->right)&&q->right->j<j; q=q->right);
p->right=q->right;
q->right=p;
}
if(M->chead[j]==NULL||M->chead[j]->i>i)
{
p->down=M->chead[j];
M->chead[j]=p;
}
else
{
for(q=M->chead[j]; (q->down)&&q->down->i<i; q=q->down);
p->down=q->down;
q->down=p;
}
}
}
}
M->tu=t;
return OK;
}
void print(CrossList M)
{
int p,q;
OLNode *pTemp;
for(p=1; p<=M.mu; p++)
{
pTemp=M.rhead[p];
for(q=1; q<=M.nu; q++)
{
if(pTemp!=NULL&&pTemp->j==q)
{
printf("%d ",pTemp->e);
pTemp=pTemp->right;
}
else
printf("0 ");
}
printf("\n");
}
}
void findPoint(CrossList M)
{
bool flag = false;
int p,q;
int minn[M.mu];
int maxx[M.nu];
maxx[0] = INT_MIN;
minn[0] = INT_MAX;
OLNode *pTemp;
for(p=1; p<=M.mu; p++)
{
pTemp=M.rhead[p];
minn[p-1] = INT_MAX;
for(q=1; q<=M.nu; q++)
{
if(pTemp!=NULL&&pTemp->j==q)
{
if(pTemp->e < minn[p-1])
{
minn[p-1] = pTemp->e;
}
pTemp=pTemp->right;
}
else
{
if(minn[p-1]>0){
minn[p-1] = 0;
}
}
}
}
for(p=1; p<=M.nu; p++)
{
pTemp=M.chead[p];
maxx[p-1] = INT_MIN;
for(q=1; q<=M.mu; q++)
{
if(pTemp!=NULL&&pTemp->i==q)
{
if(pTemp->e > maxx[p-1])
{
maxx[p-1] = pTemp->e;
}
pTemp=pTemp->down;
}
else
{
if(maxx[p-1]<0){
maxx[p-1] = 0;
}
}
}
}
for(p=1; p<=M.nu; p++){
cout<<maxx[p-1]<<" ";
}
for(int i=0; i<M.mu; i++)
{
for(int j=0; j<M.nu; j++)
{
if(minn[i]==maxx[j])//找到马鞍点
{
cout<<"第"<<i+1<<"行第"<<j+1<<"列的"<<minn[i]<<"为马鞍点"<<endl;//i+1 j+1原因:第几行第几列从1开始,而数组从0开始
flag = true;
}
}
}
if(flag == false)
{
cout<<"没有马鞍点"<<endl;
}
}
int main()
{
while(1){
CrossList M;
CreateSMatrix_OL(&M);
findPoint(M);
return 0;
}
}
前言
随着社会的发展,人们生活水平的提高,欣赏电影逐渐成为人们闲暇时的主要娱乐方式之一。随着电影在众人的娱乐生活中占据越来越重要的地位,传统手动售票方式繁琐,统计帐户的时候一张一张的记录进入到账户薄里面,容易出现错误,所以研究一个电影售票系统已经非常的重要了。设计电影院售票系统,能方便的订票,极大的提高了了工作效率。传统的电影售票都是人工服务,观看座位都是人工安排,无法体现人性化选择,加上现在人们的生活节奏越来越快,购票时间需要相应缩短以及方便电影院工作人员的管理,本系统就是为了解决这一系列问题提出的。
电影成为现今社会人们娱乐的重要项目,因此一个完善的影院售票系统为我们的出行和观影提供了方便,避免迟到错过影片和排队拥挤。人工售票的手续繁琐、效率低下给具有强烈时间观念的管理人员带来了诸多不便,影院缺少一套完善的售票系统软件,为了对售票的管理方便,因此必须开发影院售票系统。随着计算机技术的不断应用和提高,计算机已经深入到社会生活的各个角落。而采用手工售票的方法,不仅效率低、易出错、手续繁琐,而且耗费大量的人力。为了满足售票人员对售票进行高效的管理,在工作人员具备一定的计算机操作能力的前提下,特编此影院售票系统软件以提高影院的管理效率。根据对周边电影院售票系统的调查和了解,通过系统的设计,实现电影购票系统。
利用计算机进行电影院座位管理系统设计,能够通过数据库获得每个放映厅的售票情况,而且还可以利用计算机进行购票,已经售出的座位将不能再选。
设计一个电影院座位管理系统。一个电影院有多个放映厅,每个放映厅的座位数量大于100且分多行,根据电影票的不同选择不同的放映厅,然后在相应的放映厅中选择座位,座位示意图应该与实际的方位和数量相同,已经选过的座位不能再选。
流程图:
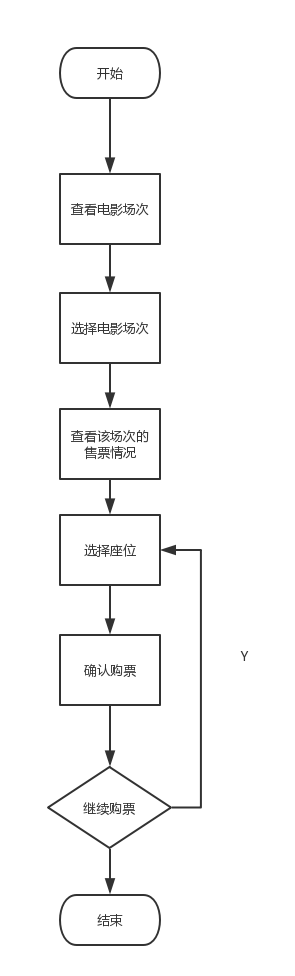
图1.21
电影院座位管理系统应包含以下几个功能:
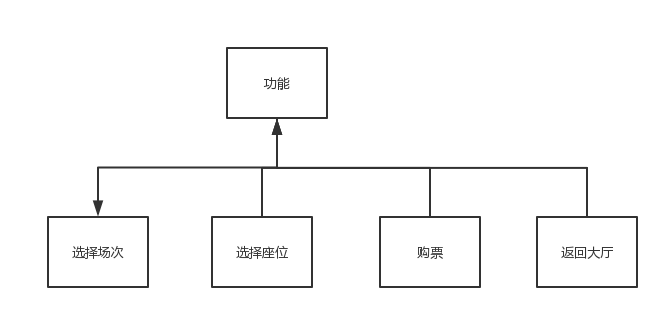
图1.22
操作系统:Microsoft Windows 10 64位
IDE:CodeBlocks 32位
编译器:GNU GCC Compiler
数据库:Sqlite3
编程语言:C/C++
图形库:ACLLib
SQLite是一款轻型的本地文件数据库,是遵守ACID的关联式数据库管理系统。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它的功能强、速度快,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。它能够支持Windows/Linux/Unix等主流的操作系统,同时能够跟很多程序语言相结合。
在进行数据库操作之前,有个问题需要说明,就是SQLite的数据类型,和其他的数据库不同,Sqlite支持的数据类型有他自己的特色:Typelessness(无类型)。 SQLite是无类型的,这意味着你可以保存任何类型的数据到你所想要保存的任何表的任何列中, 无论这列声明的数据类型是什么。
而大多数的数据库在数据类型上都有严格的限制,在建立表的时候,每一列都必须制定一个数据类型,只有符合该数据类型的数据可以被保存在这一列当中。而在SQLite 2.X中,数据类型这个属性只属于数据本生,而不和数据被存在哪一列有关,也就是说数据的类型并不受数据列限制(有一个例外:INTEGER PRIMARY KEY,该列只能存整型数据)。
但是当SQLite进入到3.0版本的时候,这个问题似乎又有了新的答案,SQLite的开发者开始限制这种无类型的使用,在3.0版本当中,每一列开始拥有自己的类型,并且在数据存入该列的时候,数据库会试图把数据的类型向该类型转换,然后以转换之后的类型存储。当然,如果转换被认为是不可行的,SQLite仍然会存储这个数据,就像他的前任版本一样。
举个例子,如果你企图向一个INTEGER类型的列中插入一个字符串,SQLite会检查这个字符串是否有整型数据的特征, 如果有而且可以被数据库所识别,那么该字符串会被转换成整型再保存,如果不行,则还是作为字符串存储。
诚然SQLite允许忽略数据类型, 但是仍然建议在你的Create Table语句中指定数据类型. 因为数据类型对于你和其他的程序员交流, 或者你准备换掉你的数据库引擎时能起到一个提示或帮助的作用. SQLite支持常见的数据类型, 如:
1.NULL,值是NULL
2.INTEGER,值是有符号整形,根据值的大小以1,2,3,4,6或8字节存放
3.REAL,值是浮点型值,以8字节IEEE浮点数存放
4.TEXT,值是文本字符串,使用数据库编码(UTF-8,UTF-16BE或者UTF-16LE)
5.BLOB,只是一个数据块,完全按照输入存放(即没有准换)
2.22 SQLite的5个主要的函数:
sqlite3_open(), 打开数据库
sqlite3_exec(),执行非查询的sql语句
sqlite3_prepare(),准备sql语句,执行select语句或者要使用parameter bind时,用这个函数(封装了sqlite3_exec).
sqlite3_step(),在调用sqlite3_prepare后,使用这个函数在记录集中移动。
sqlite3_close(),关闭数据库文件
SQLiteStudio是一个基于QT写的SQLite数据的可视化编辑和查看的开源软件软件,使用非常简单。进入sqlitestudio官网,下载它的已经编译可用的软件包,找到跟你系统匹配的软件包,下载到自己的电脑的指定的目录中,第一次打开,需要设置默认的软件语言,这个可视化操作软件是支持多语言的,如下图所示操作
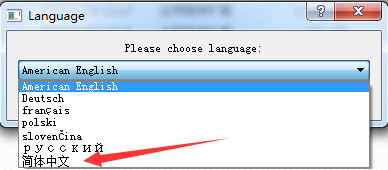
图2.31
可以可视化操作编辑我们的数据库进行增删改查操作,十分方便。
首先创建一个数据库,在数据库中建立四张表,分别名为t1,t2,t3,t4,分别代表放映厅1,放映厅2,放映厅3,放映厅4。

图2.41
在每个放映厅的表中,只有一条string类型的数据,售票情况用0和1表示,0表示该位置已售出,1表示该位置尚未售出,如下图所示。

图2.42
数据库的查询SQL语句为(以放映厅1为例):SELECT * from t1,就可以查到表t1中的所有数据。
数据库的连接只需通过Sqlite3提供的C/C++接口,即可实现用户操作与数据资源的连接,并可对相关的数据库信息进行操作。
sqlite3 *db;//定义一个数据库指针
rc = sqlite3_open(“camera.db”, &db);//链接数据库
sql = “SELECT * from t1”;//把我们要执行的数据库查询SQL语句存入sql变量中
rc = sqlite3_exec(db, sql, callback, (void*)data, &zErrMsg);//执行SQL语句并调用回调函数
sqlite3_close(db);//断开与数据库的链接,释放相应的资源
数据库的更新SQL语句为(以放映厅1为例):UPDATE t1 set zuowei =1,就可以将表t1中的zuowei的值更新为1。
数据库的修改只需通过Sqlite3提供的C/C++接口,编辑好相应的SQL语句,即可实现用户操作与数据资源的连接,并可对相关的数据库信息进行操作。
rc = sqlite3_open(“1.db”, &db);//链接同目录下名为1.db的数据库
sql = “UPDATE t1 set zuowei = ‘123’”;//将我们的数据库更新语句赋值给变量sql1
const char* p1 = sql.data();//将string类型的sql变量赋值给const char*类型的p1
rc = sqlite3_exec(db, p1, callback0, (void*)data, &zErrMsg);//执行数据库更新语句
sqlite3_close(db);//断开与数据库的链接闭关释放相应资源。

图3.1
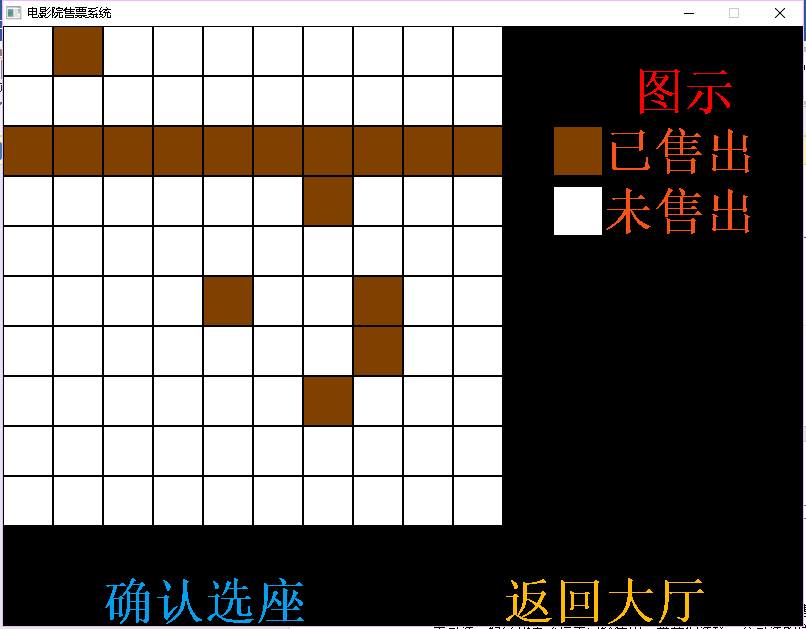
图3.2

图3.3
(4)当用户点击返回大厅时,将返回上一界面,用户可以重新选择放映厅。
源代码:maplefan/cinema
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
我们每个活在世上的人,为了能够参与各种社会活动,都需要一个用于识别自己的标志。也许你觉得名字或是身份证就足以代表你这个人,但是这种代表性非常脆弱,因为重名的人很多,身份证也可以伪造。最可靠的办法是把一个人的所有基因序列记录下来用来代表这个人,但显然,这样做并不实际。而指纹看上去是一种不错的选择,虽然一些专业组织仍然可以模拟某个人的指纹,但这种代价实在太高了。
而对于在互联网世界里传送的文件来说,如何标志一个文件的身份同样重要。比如说我们下载一个文件,文件的下载过程中会经过很多网络服务器、路由器的中转,如何保证这个文件就是我们所需要的呢?我们不可能去一一检测这个文件的每个字节,也不能简单地利用文件名、文件大小这些极容易伪装的信息,这时候,我们就需要一种指纹一样的标志来检查文件的可靠性,这种指纹就是我们现在所用的Hash算法(也叫散列算法)。
散列算法(Hash Algorithm),又称哈希算法,杂凑算法,是一种从任意文件中创造小的数字「指纹」的方法。与指纹一样,散列算法就是一种以较短的信息来保证文件唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。因此,当原有文件发生改变时,其标志值也会发生改变,从而告诉文件使用者当前的文件已经不是你所需求的文件。
这种标志有何意义呢?之前文件下载过程就是一个很好的例子,事实上,现在大部分的网络部署和版本控制工具都在使用散列算法来保证文件可靠性。而另一方面,我们在进行文件系统同步、备份等工具时,使用散列算法来标志文件唯一性能帮助我们减少系统开销,这一点在很多云存储服务器中都有应用。
当然,作为一种指纹,散列算法最重要的用途在于给证书、文档、密码等高安全系数的内容添加加密保护。这一方面的用途主要是得益于散列算法的不可逆性,这种不可逆性体现在,你不仅不可能根据一段通过散列算法得到的指纹来获得原有的文件,也不可能简单地创造一个文件并让它的指纹与一段目标指纹相一致。散列算法的这种不可逆性维持着很多安全框架的运营,而这也将是本次课程设计讨论的重点。
使用Hash的数据结构叫做散列表,主要是为了提高查询的效率。也有直接译作哈希表,也叫Hash表,
Hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,它采用了函数映射的思想将记录的存储位置与记录的关键字关联起来,从而能够很快速地进行查找。
一个优秀的 hash 算法,将能实现:
(1)正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
(2)逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
(3)输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
(4)冲突避免:很难找到两段内容不同的明文,使得它们的 hash 值一致(发生冲突)。即对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。
(1)数字分析法
(2)直接定址法
(3)除留余数法
(1)线性探测法
(2)平方取中法
(3)拉链法
Hash主要应用于数据结构中和密码学中。
用于数据结构时,主要是为了提高查询的效率,这就对速度比较重视,对抗碰撞不太看中,只要保证hash均匀分布就可以。
在密码学中,hash算法的作用主要是用于消息摘要和签名,换句话说,它主要用于对整个消息的完整性进行校验。
我们这里主要研究Hash用于数据结构中的作用。
(1)首先需要随机生成中国人姓名的汉字拼音形式。
(2)随机生成3000个人名列表,并保存在文本文件中,在构建哈希表时读入。
(3)实现3种不同的哈希函数,并在建表的时候提供对应的冲突处理方案。
(4)比较不同方法的平均查找长度
2.功能要求
(1)随机姓名生成。
名字的长度不少于3个字符,不多于10个字符,为了符合要求,我们随机选用单姓的拼音加上一个随机的文字拼音组成随机姓名的拼音形式,并保存在文本文件中。
(2)建立Hash表功能。
分别通过直接取址法,平方取中法和除留余数法对姓名拼音的第一个字母,倒数第二个字母,倒数第一个字母的组合公式进行哈希,建立哈希表。
(3)实现Hash查找函数。
实现Hash查找函数并返回查找需要的次数,如果查找失败,返回0。
开发环境
IDE:DevC++
编译器:GNU GCC Compiler
操作系统:Windows 10 64位
该程序可以分为以下几个模块:
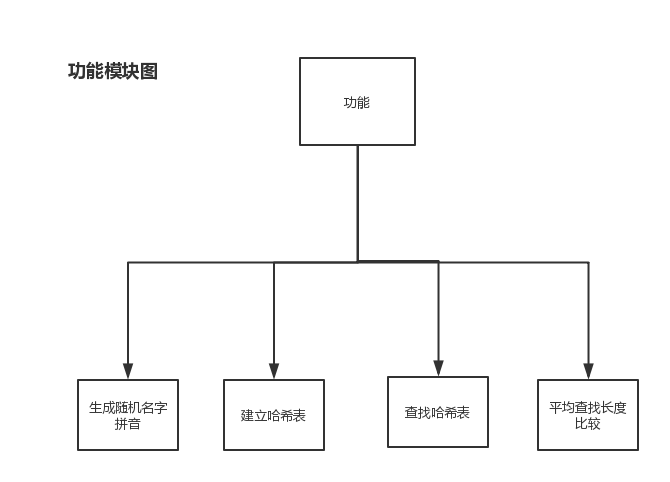
1.生成随机名字拼音模块:随机生成名字拼音并保存在文本文件中。
2.建立Hash表模块:通过3种不同的算法建立不同的Hash表。
3.查找Hash表模块:通过3种不同的算法对应的查找函数查找Hash表中是否存在我们的名字,并返回查找次数,如果不存在该名字,则返回0。
4.平均查找长度比较模块:通过返回的查找次数求和并求平均数,比较不同的Hash表的查找效率。
本章是根据软件工程知识,对概要设计的具体实现。通过对每个模块的功能进行描述,绘出功能流程图,编写代码,最终展示出相应的页面。使得整个设计变成一个可运行物理实体,从而达到本次设计的最终目的。
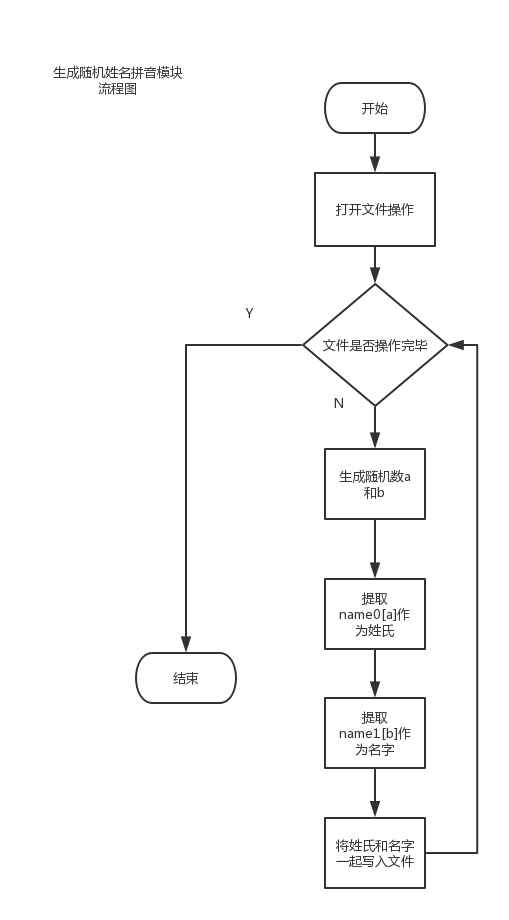
首先,我建立了两个字符串数组name0和name1,分别保存我们所需要用到的姓氏和名字的拼音,一共存储了444个姓氏的拼音和305个名字的拼音。
然后实现了makeName()这个函数,函数通过调用头文件time.h中的随机函数rand()生成随机数,并对随机数分别mod 444和mod 305,获得我们要的数组范围内索引,从两个数组中分别取得姓和名,拼接成我们所要的随机姓名。
同时,我们通过C语言的文件操作,以只写模式打开同目录下的name.txt,并将我们生成的随机姓名存入该文本文件中,一个姓名占据一行,最后关闭文件操作。
流程图如下:
模块函数实现如下:
void makeName()
{
srand((int)time(0));//让我们的随机数根据系统时间变化
FILE *fp;//建立一个文件操作指针
if ( (fp=fopen("name.txt","w+"))==NULL) // 以追加只写模式打开文件操作
{
printf("File open error!\n");
}
for(int i = 0; i<3000; i++)
{
int a = rand()%444;//用来作为姓氏的数组索引
int b = rand()%305;//用来作为名字的数组索引
char tempName[12];
strcpy(tempName,name0[a]);//将随机的姓复制到tempName中
strcat(tempName,name1[b]);//将随机的名复制到tempName中
fprintf( fp, "%s\n", tempName );//将tempName写入文件
}
fclose(fp);//关闭文件操作
}
我们分别通过不同的方法建立了3个不同的Hash表,分别名为hashmap1,hashmap2,hashmap3,hashmap4,其中hashmap4是hashmap3的补充,即当hashmap3发生冲突时我们的数据会存入hashmap4。
建立三个不同的Hash表我们使用了3个不同的函数,分别名为myHash1(),myHash2(),myHash3(),分别采用了直接取址法、平方取中法、除留余数法进行建表,并在函数中提供了相应的冲突解决方案。
由于我们的名字是由字符串组成,我们希望生成相应的数字用来当哈希表的索引,所以我们在myHash1()中使用公式int k = (a[0]-‘a’)*26*26 + (a[strlen(a)-2]-‘a’)*26 + (a[strlen(a)-1]-‘a’)生成索引。如果发生冲突我们就一直往后找直到找到空位置为止,把数据存到该空位置中。
在myHash2()中使用公式long long int k = (a[0]-‘a’)*26*26 + (a[strlen(a)-2]-‘a’)*26 + (a[strlen(a)-1]-‘a’)生成一个大数k,如果k小于或等于4位数,则直接用k作为索引,如果k大于4位数,则使用k的中间4位作为我们的索引。如果发生冲突我们就一直往后找直到找到空位置为止,把数据存到该空位置中。
在myHash3()中使用公式int k = (a[0]-‘a’)*26*26 + (a[strlen(a)-2]-‘a’)*26 + (a[strlen(a)-1]-‘a’)来生成一个数,并对这个数取mod 2777,其中2777是一个接近我们的数组大小的素数,如果发生冲突我们把冲突的数据按顺序放到hashmap4中。
流程图如下:

模块函数实现如下:
void myHash1()
{
memset(hashmap1,0,sizeof(hashmap1));//将hashmap1字符串数组中所有的字符串置为空
FILE *fpRead;
if ( (fpRead=fopen("name.txt","r"))==NULL) // 打开文件
{
printf("File open error!\n");
}
char a[12];
for(int i = 0; i<3000; i++)
{
fscanf(fpRead,"%s",&a);//读取name.txt文件的一行给字符串数组a
int k = (a[0]-'a')*26*26 + (a[strlen(a)-2]-'a')*26 + (a[strlen(a)-1]-'a');
int index = k;
while(hashmap1[index][0]!='\0')
{
index++;
}
strcpy(hashmap1[index],a);//将读取到的a存入hashmap1的该位置
}
}
void myHash2()
{
memset(hashmap2,0,sizeof(hashmap2));//将hashmap2字符串数组中所有的字符串置为空
FILE *fpRead;
if ( (fpRead=fopen("name.txt","r"))==NULL) // 打开文件
{
printf("File open error!\n");
}
char a[12];
int index = 0;
for(int i = 0; i<3000; i++)
{
fscanf(fpRead,"%s",&a);//读取name.txt文件的一行给字符串数组a
long long int k = (a[0]-'a')*26*26 + (a[strlen(a)-2]-'a')*26 + (a[strlen(a)-1]-'a');
k = k*k;//平方
if(k<10000)
{
index = k;
}
else//取中
{
int dight = getDigit(k);
for(int i = 0; i<(dight-4)/2 ; i++)
{
k = k/10;
}
index = k%10000;
}
while(hashmap2[index][0]!='\0')
{
index++;
}
strcpy(hashmap2[index],a);//将a存到对应的位置
}
}
void myHash3()
{
int count = 0;
memset(hashmap3,0,sizeof(hashmap3));//将hashmap3字符串数组中所有的字符串置为空
memset(hashmap4,0,sizeof(hashmap4));//将hashmap4字符串数组中所有的字符串置为空
FILE *fpRead;
if ( (fpRead=fopen("name.txt","r"))==NULL) // 打开文件
{
printf("File open error!\n");
}
char a[12];
int index = 0;
for(int i = 0; i<3000; i++)
{
fscanf(fpRead,"%s",&a);//读取name.txt文件的一行给字符串数组a
int k = (a[0]-'a')*26*26 + (a[strlen(a)-2]-'a')*26 + (a[strlen(a)-1]-'a');
index = k%2777;
if(strlen(hashmap3[index])==0)
{
strcpy(hashmap3[index],a);//如果不存在字符串,放进hashmap3对应位置
}
else
{
strcpy(hashmap4[count],a);//否则放到hashmap4字符串数组中
count++;
}
}
}
查找Hash表模块分别用myHash1Find(),myHash2Find(),myHash3Find()三个函数实现,根据建表时的方法和冲突解决方案对应的去查找我们要的数据是否存在,同时都设置了计数器,当找到了我们要的数据时,返回查找次数,否则返回0表示没有找到我们要的数据。
流程图如下:
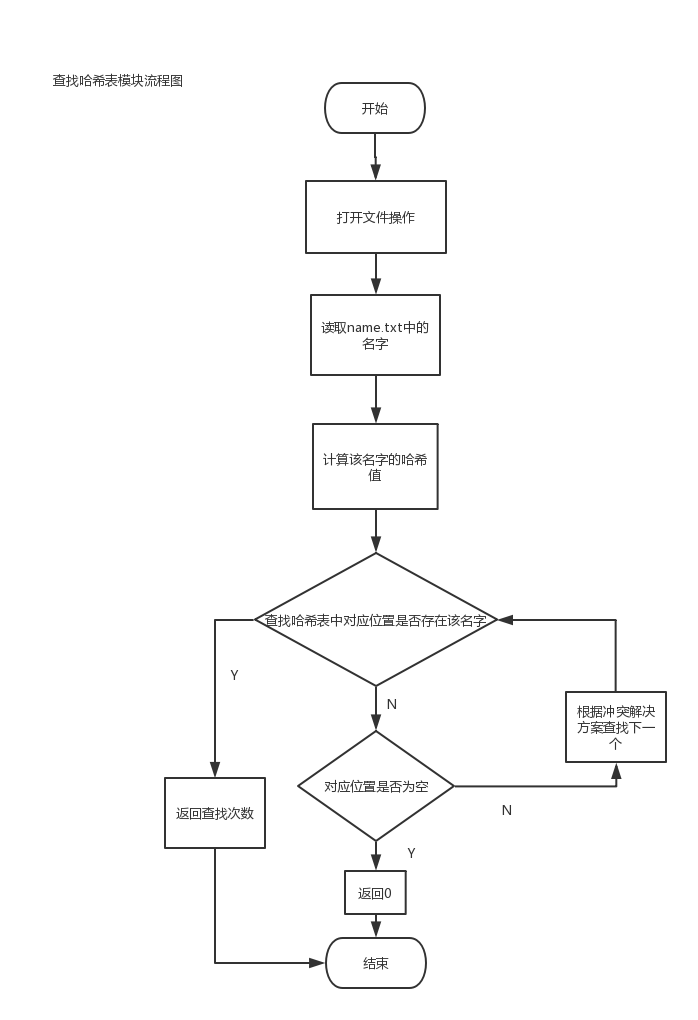
具体实现如下:
int myHash1Find(char* a) //存在返回查找次数,不存在返回0
{
int k = (a[0]-'a')*26*26 + (a[strlen(a)-2]-'a')*26 + (a[strlen(a)-1]-'a');
int temp = k;
while(1)
{
if(strcmp(hashmap1[temp],a)==0)
{
return temp-k+1;
}
else if(strlen(hashmap1[temp])!=0)
{
temp++;
}
else
{
return 0;
}
}
return temp-k+1;
}
int myHash2Find(char* a) //存在返回查找此时,不存在返回0
{
long long int k = (a[0]-'a')*26*26 + (a[strlen(a)-2]-'a')*26 + (a[strlen(a)-1]-'a');
int temp ;
k = k*k;//平方
if(k<10000)
{
temp = k;
}
else//取中
{
int dight = getDigit(k);//计算大数k的位数,根据位数来取中间4位数
for(int i = 0; i<(dight-4)/2 ; i++)
{
k = k/10;
}
temp = k%10000;
}
int num = temp;
while(1)
{
if(strcmp(hashmap2[temp],a)==0)
{
return temp-num+1;
}
else if(strlen(hashmap2[temp])!=0)
{
temp++;
}
else
{
return 0;
}
k++;
}
}
int myHash3Find(char* a) //存在返回查找此时,不存在返回0
{
int k = (a[0]-'a')*26*26 + (a[strlen(a)-2]-'a')*26 + (a[strlen(a)-1]-'a');
int temp = k%2777;
if(strcmp(hashmap3[temp],a)==0)
{
return 1;
}
else
{
int count = 0;
while(strlen(hashmap4[count])!=0)
{
if(strcmp(hashmap4[count],a)==0)
{
return count+1;
}
count++;
}
return 0;
}
}
平均查找长度模块由函数compareHash实现,分别通过文件操作读入name.txt中的3000个姓名并查找该姓名,将查找次数求和,最后输入查找总次数除以3000即可。
流程图如下:
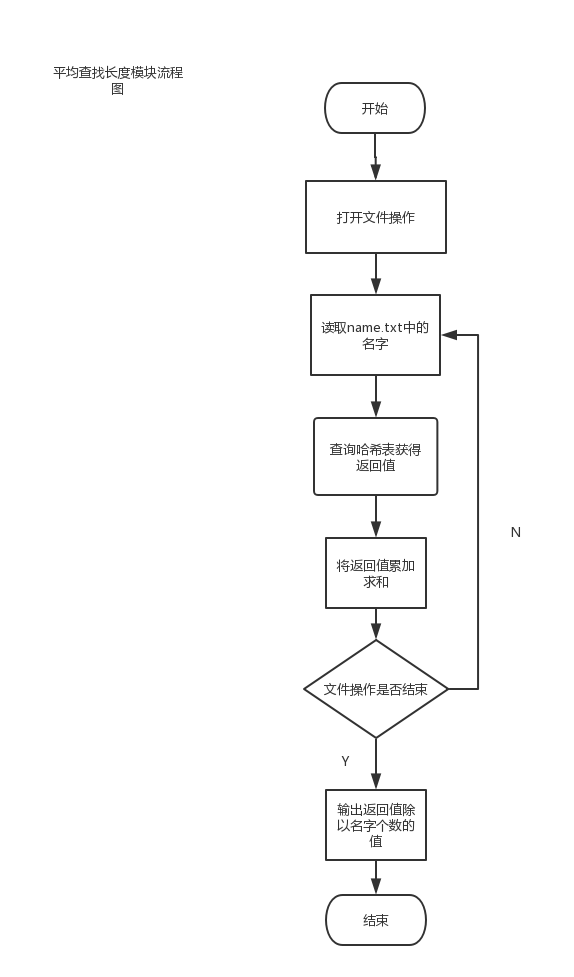
实现函数如下:
void compareHash() //比较平均查找长度
{
double hash1Count = 0;//用来存储使用hash1查找函数时用的次数和
double hash2Count = 0;//用来存储使用hash2查找函数时用的次数和
double hash3Count = 0;//用来存储使用hash3查找函数时用的次数和
FILE *fpRead;
if ( (fpRead=fopen("name.txt","r"))==NULL) // 打开文件
{
printf("File open error!\n");
}
char a[12];
for(int i = 0; i<3000; i++)
{
fscanf(fpRead,"%s",&a);//读取name.txt文件的一行给字符串数组a
hash1Count = hash1Count + myHash1Find(a);
hash2Count = hash2Count + myHash2Find(a);
hash3Count = hash3Count + myHash3Find(a);
}
printf("hash1算法查找3000个名字的总查找次数为:%.2f\n",hash1Count/3000.00);
printf("hash2算法查找3000个名字的总查找次数为:%.2f\n",hash2Count/3000.00);
printf("hash3算法查找3000个名字的总查找次数为:%.2f\n",hash3Count/3000.00);
}
软件测试是软件开发中必不可少的阶段。本章中,通过各种测试方法和多个测试用例,对应用进行测试,以期找出系统中可能导致系统出现问题的地方,使得该应用成为一个稳定的,高效的,能够达到用户标准的应用。
经过多次测试调试,我们的程序可以正常生成随机姓名拼音,hash函数也正常运行。
生成的3000个姓名拼音如下:

效率比较如下:
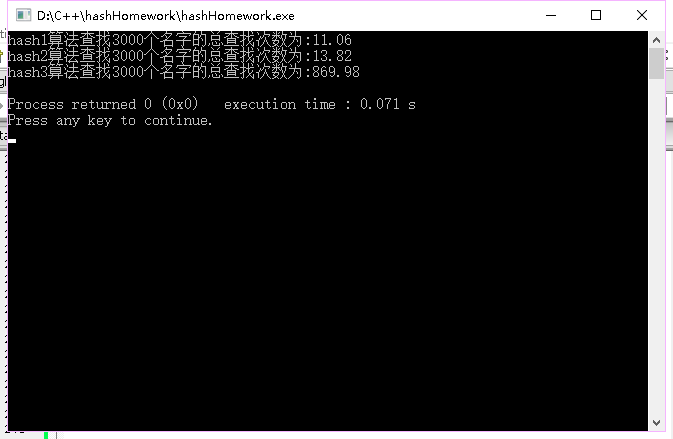
最终我们发现我们的hash1算法查找效率最高,但使用的空间最多,hash3算法查找效率极低,但使用的空间较少,而hash2算法使用空间较少,效率也比较高。
设计一个日期类,要求重载其输入输出运算符,方便输入输出(输入和输出的格式为1970.09.25),并要求实现日期加和减运算(即(1)一个日期减另一个日期返回值为这两个日期之间相隔的天数;(2)一个日期减一个整数8则返回比这个日期早8天的日期;(3)一个日期加一个整数8则返回比这个日期晚8天的日期),并能比较两个日期的先后顺序,在main函数中首先要求用户输入两个日期,然后首先输出第一个日期加100天和减100天是哪一天?再输出第一个日期与第二个日期之间相隔多少天?最后将两个日期按先后次序输出。(考虑闰年,考虑月份不同)
#include<iostream>
#include<algorithm>
#include <ctime>
using namespace std;
class Date
{
private:
int year;
int month;
int day;
public:
Date()
{
year = 0;
month = 0;
day = 0;
}
Date(int a,int b,int c)
{
year = a;
month = b;
day = c;
}
~Date()
{
}
int getYear()
{
return this->year;
}
void setYear(int year)
{
this->year = year;
}
int getMonth()
{
return this->month;
}
void setMonth(int month)
{
this->month = month;
}
int getDay(int day)
{
return this->day;
}
void setDay()
{
this->day =day;
}
bool IsLeapYear(int year)
{
if(year % 400 || (year % 4 && year % 100))
return true;
return false;
}
int YearsOfMonth(int year, int month)
{
int day;
int days[13] = { 0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
day = days[month];
if (month == 2)
day += IsLeapYear(year);
return day;
}
Date operator+(int a)
{
Date b;
b.year = this->year;
b.month = this->month;
b.day = this->day + a;
while(b.day > YearsOfMonth(b.year,b.month))
{
if(b.month == 12)
{
b.month = 1;
b.year++;
}
else
{
b.month++;
}
b.day = b.day - YearsOfMonth(b.year,b.month);
}
return b;
}
Date operator-(int a)
{
Date b;
b.year = this->year;
b.month = this->month;
b.day = this->day - a;
while(b.day <= 0)
{
if(b.month == 1)
{
b.month = 12;
b.year--;
}
else
{
b.month--;
}
b.day = b.day + YearsOfMonth(b.year,b.month);
}
return b;
}
int daysOfDate(Date d)//计算一共的天数
{
int days=d.day;
for(int y=1; y<d.year; y++) //计算年
days= days + 365+IsLeapYear(d.year);
for(int m=1; m<d.month; m++) //计算月
days= days + YearsOfMonth(d.year,d.month);
return days;
}
int operator-(Date a)
{
Date b;
b.year = this->year;
b.month = this->month;
b.day = this->day ;
int days1=daysOfDate(b);
int days2=daysOfDate(a);
return days1 - days2;
}
bool operator>(Date a)
{
Date b;
b.year = this->year;
b.month = this->month;
b.day = this->day ;
int days1=daysOfDate(b);
int days2=daysOfDate(a);
if(days1 >= days2)
{
return true;
}
return false;
}
friend ostream& operator<<(ostream& out, const Date &a)
{
out<<a.year<<"."<<a.month<<"."<<a.day;
return out;
}
friend istream& operator>>(istream& in, Date &a)
{
in >>a.year;
cin.get();
in>>a.month;
cin.get();
in>>a.day;
return in;
}
};
int main()
{
Date a;
Date b;
cin>>a;
cin>>b;
cout<<a+100<<endl;
cout<<a-100<<endl;
cout<<a-b<<endl;
if(a>b)
{
cout<<b<<endl;
cout<<a<<endl;
}
else
{
cout<<a<<endl;
cout<<b<<endl;
}
}
米兔爸爸为了让小米兔好好锻炼身体,便给小米兔设置了一个挑战——跳格子。
要吃到自己心爱的胡萝卜,小米兔需要跳过面前一些格子。现有 N 个格子,每个格子内都写上了一个非负数,表示当前最多可以往前跳多少格,胡萝卜就放在最后一个格子上。米兔开始站在第 1 个格子,试判断米兔能不能跳到最后一个格子吃到胡萝卜呢?
输入为 N 个数字 (N<10),用空格隔开,第 i个数字 si(100≤si<10) 表示米兔站在第 i个格子上时,最多能往前跳的格数。
若米兔能跳到最后一个格子上吃到胡萝卜,输出 “true“,否则输出 “false“
2 0 1 0 0 3 4
false
#include <bits/stdc++.h>
#include<iostream>
#include<map>
using namespace std;
int main()
{
int b;
vector<int>a;
bool flag = false;
while(cin>>b)
{
a.push_back(b);
if (cin.get() == '\n')
break;
}
int mitu = 0;
while(mitu<a.size()){
mitu = mitu + a[mitu];
if(mitu == a.size()-1){
flag = true;
break;
}
if(a[mitu] == 0){
break;
}
}
if(flag){
cout<<"true"<<endl;
}
else
cout<<"false"<<endl;
}
给定一个整数N,求N!的末尾有多少个0.
输入为一个整数N,1 <= N <= 1000000000.
输出为N!末尾0的个数
3 60 100 1024 23456 8735373
0 14 24 253 5861 2183837
#include <bits/stdc++.h>
using namespace std;
int main()
{
int num = 0;
while(cin>>num)
{
int cnt = 0;
for(int i = 1; i<num; i++)
{
int j = i;
while(j%5 == 0)
{
cnt++;
j= j/5;
}
}
cout<<cnt<<endl;
}
return 0;
}