内容:
第一章
我们首先看一下组成PDF文件的各种对象,以及它们是如何结合在一起的。
第二章
在本章中,我们将讨论PDF的核心方面——它的成像模型。我们学习如何创建页面并在其上绘制一些图形。
第三章
继续对核心成像模型的讨论,在本章中我们将探讨如何将光栅图像合并到您的PDF内容中。
第四章
接下来,我们将学习如何合并最后一种常见的PDF内容——文本类型。当然,如果没有字体和象形文字,PDF格式的文本讨论是不完整的。
第五章
PDF不仅仅是静态内容。本章将介绍PDF可以获得交互性的各种方法,特别是围绕在文档内部和文档之间启用导航的方式。
第六章
本章探讨注释的特殊对象,这些对象是在常规内容的基础上绘制的,以支持从交互链接到3D到视频和音频的所有内容。
第七章
接下来,我们将讨论如何在PDF语言中提供交互式表单。
第八章
本章演示如何通过在PDF中嵌入文件,以类似于ZIP存档的方式使用PDF。
第九章
本章解释如何将视频和音频内容作为丰富内容的一部分引用到PDF中或嵌入到PDF中。
第十章
本章介绍了可选内容,这些内容仅在特定时间出现,例如在屏幕上,而不是打印时或仅针对某些用户。
第十一章
本章讨论如何通过使用类似HTML的结构(如段落和表)来为内容添加语义丰富。
第十二章
本章探讨了将元数据合并到PDF文件的各种方法,从最简单的文档级别字符串到附加到indi-vidued对象的富XML。
第十三章
最后,本章介绍了基于PDF的各种开放国际标准,包括完整的PDF标准本身(iso 32000-1)、各种子集(如PDF/A和PDF/X)以及 相关工作(如PAdES)。
第一章
我们将直接进入PDF文件格式的构建块开始我们对PDF的探索。使用这些块,您将看到PDF是如何构造成基于页面的格式的。
PDF对象
PDF文件的核心部分是PDF标准(Iso 32000)所指的“事物”集合,有时也称为COS对象。
这个对象不是“面向对象编程”这个词意义上的对象;相反,它们是PDF所赖以生存的基石。有九种类型的对象:null,boolean, integer, real, name, string, array, dictionary, and stream.
分别为空、布尔、整数、实数、名称、字符串、数组、字典和流。
让我们看看这些对象类型中的每一种,以及它们是如何序列化成PDF文件的。然后,您将看到如何接受这些对象类型,并使用它们构建更高级别的构造和 PDF格式本身。
Null Objects(空对象)
如果实际写入文件,则NULL对象就是四个简单的NULL字符。它等同于一个缺失值,这就是它为什么在PDF中很少看到的原因。如果你有机会与空值一起工作,请确保仔细地品味ISO 32000中涉及其处理的微妙之处。
Boolean Objects(布尔对象)
布尔对象表示为true和false的逻辑值,相应的在PDF中也是,既可以为true,也可以为false。
在编写PDF时,您将始终使用true或false。但是,如果您正在阅读/解析PDF并且希望能够容忍,请注意写得不好的PDF可能会使用其他的大写形式,包括首字母大写(True或False)或全部大写(TRUE或FALSE)。
Numeric Objects(数字对象)
PDF支持两种不同类型的数字对象——整型和实形——来表示它们的数学等价物。虽然旧版本的PDF已经声明实现了与Adobe以前的实现相匹配的限制,但这些不应该再被视为文件格式的限制(也不应该被任何特定的实现所限制)。
虽然PDF支持64位数字(以便启用非常大的文件),但您会发现大多数PDF实际上并不需要它们。然而,如果你正在阅读PDF,你可能真的会遇到他们,所以请做好准备。
整数数字对象由一个或多个十进制数字组成,可以选择前面加上一个符号,表示一个有符号的值(10进制表示)。示例1-1显示了一些整数的例子。
Example 1-1. Integers
1 -2 +100 612
实数数字对象由一个或多个十进制数字组成,其中包含一个可选符号和一个前导、尾随或嵌入的句点,表示一个有符号的实值。与PostScript不同,PDF不支持 科学/指数格式,也不支持非十进制。
虽然在PDF中使用了术语“real”来表示对象类型,但是给定查看器的实际实现可能使用double、float甚至定点数。因为实现可能会有所不同,小数位的精度可能也不一样。因此,为了可靠性和文件大小的考虑,建议不要写超过小数点的四位。
示例1-2显示了一些在PDF中实数是什么样子的示例。
Example 1-2. Reals
0.05 .25 -3.14159 300.9001
Name Objects(名字对象)
PDF中的名字对象是唯一的字符序列(字符代码0除外,ASCII NULL除外),通常在有固定值集的情况下使用。姓名被写入PDF格式时,带有一个转义“/”字符,后面跟着一个UTF-8字符串,对任何非规则字符都有一个特殊的编码形式。非规则字符是那些定义在0x21(!)到0x7e(~)范围外的字符, 以及任何空白字符(见表1-1)。这些非规则字符以#(数字符号)开始编码,然后是字符的两位十六进制代码。
由于其独特的性质,您将写入PDF的大多数名称都是在ISO 32000中预先定义的,或者是从外部数据(例如字体或颜色名称)派生出来的。
如果您需要创建自己的非外部数据自定义名称(例如私有元数据),如果您希望您的文件被视为有效的PDF,则必须遵循ISO 32000-1:2008附件E中定义的二等名称规则。第二个类名以四个字符的ISO注册前缀开头,后面跟着下划线(_),然后是键名。一个例子包括在示例1-3的末尾。
Example 1-3. Names
/Type /ThisIsName37 /Lime#20Green /SSCN_SomeSecondClassName
String Objects(字符串对象)
字符串被序列化为PDF格式,它们只是一系列(0或更多个)8比特字节,这些字节要么是用括号括起来的文字字符,要么是用尖括号括起来的十六进制数据。
一个文本字符串包含任意数量的8比特字符,这些字符被括在括号中。因为任何8位值都可能出现在字符串中,所以单边的括号
和反斜杠是通过使用反斜杠来进行特殊转义处理的特殊值。此外,反斜杠可以与特殊的\ddd符号一起使用以指定其他字符值。
前面关于字符串的讨论是关于如何将值序列化为PDF文件,而不一定是PDF处理器如何在内部处理这些值。当这样的内部处理结束时 在标准的范围内,重要的是要记住,不同的文件序列化可以产生相同的内部表示(例如(A\053 B)和(A B),在示例1-4中)。
文字字符串有几个不同的变体:
ASCII:只包含ASCII字符的字节序列。
PDFDocEncoded:按照PDFDocEncode编码的字节序列(ISO 32000-1:2008,7.9.2.3)。
Text:编码为PDFDocEncoding或UTF-16BE(带有前导字节顺序标记)的字节序列。
Date:格式为D:YYYYMMDDHHmmSSOHH’mm的ASCII字符串(ISO 32000-1:2008,7.9.4)。
日期作为字符串的一种类型,在1.1版中添加到PDF中。
这对于在字符串对象中包含更多人类可读的任意二进制数据或Unicode值(UCS-2或UCS-4)非常有用。数字的数目位数必须始终为偶数,可以在数字对之间添加空白字符,以提高人的可读性。
示例1-4在PDF中显示了几个字符串示例。
Example 1-4. Strings
(Testing) % ASCII (A\053B) % 形如 (A+B) (Français) % PDFDocEncoded <FFFE0040> % Text with leading BOM (D:19990209153925-08'00') % Date <1C2D3F> %任意二进制数据
百分比符号(%)表示注释,它后面的任何文本都会被忽略。
前面关于字符串的讨论是关于如何将值序列化为PDF文件,而不一定是PDF处理器如何在内部处理这些值。同时这样的内部处理超出了标准的范围,记住不同的文件序列化可以产生相同的内部表示这一点很重要。(例如A\053B)和(A+B)(在实例1-4中)
Array Objects(数组对象)
数组对象是包含在方括号([和])中并由空白分隔的其他对象的异构集合。你可以将任意类型的对象混合和匹配在一个数组里,PDF在很多地方都利用了这一点。数组也可以是空的(即包含零元素)。
当一个数组只包含一个一维时,就可以构造一个多维数组的等价物。这个结构在PDF中不经常使用,但它确实使用出现在一些地方,例如数据结构中的顺序数组,称为可选内容组词典。
PDF数组中的元素数没有限制。但是,如果您找到了一个可以替代大规模数组的方法(例如单个孩子结点数组的页面树),那么最好避免使用它们。
在例子1-5中给出了数组的一些例子。
Example 1-5. Arrays
[ 0 0 612 792 ] % 全是整数的4个元素数组 [ (T) –20.5 (H) 4 (E) ] % 由string(字符串),real(实型),integer(整数)组成的5个元素的数组 [ [ 1 2 3 ] [ 4 5 6 ] ] % 由2个数组元素构成的数组
Dictionary Objects(字典对象)
由于它是几乎所有高级对象的基础,PDF中最常见的对象是字典对象。它是键/值对的集合,也称为关联表。每个键总是一个名字对象(Name Objects),但该值可能是任何其他类型的对象,包括另一个字典,甚至NULL。
当值为NULL时,它被视为该键不存在。因此,最好不要写这种键,以便节省处理时间和空间大小。
字典用双尖括号(<<和>>)括起来。在这些括号内,键可以按任何顺序显示,紧跟它们的是值。哪些键出现在字典中由正在被创作的高级对象的定义(在ISO 32000中)确定。
虽然许多现有的实现倾向于按字母顺序编写键,但这既不是必须的,也不是被期望的。实际上,不应该对字典处理做出任何假设 ——可以按任何顺序读取和处理键。包含相同键两次的字典无效,对应的值未定义。最后,虽然在键/值对之间换行提高了人类的可读性,但这也不是必需的,只会增加文件的总大小。
字典中的键/值对的数量没有限制。
示例1-6显示了一些示例。
Example 1-6. Dictionaries
% 一个更具可读性的字典。 << /Type /Page /Author (Leonard Rosenthol) /Resources << /Font [ /F1 /F2 ] >> >> % 一个删掉所有空格的字典 <</Length 3112/Subtype/XML/Type/Metadata>>
Name trees
名称树的用途类似于字典,因为它提供了将键与值相关联的方法。但是,与字典中不同的是,键是字符串对象,而不是名字对象,它们是按标准Unicode排序规则算法排序的。
这个概念被称为名称树,因为有一个“根”字典(或节点)引用一个或多个子字典/节点,它们本身可以引用一个或多个子字典/节点。,从而创建树状结构的许多分支。
根节点保存一个键,这个键可以是任意一个名称(用于简单树)或子节点(用于更复杂的树)。在复杂树的情况下,每个中间节点都有一个子节点的键,每个分支的最终节点将包含名称键。它是Names键的数组值,通过交替键/值指定键及其值,如例1-7所示。
Example 1-7. 只有几个名字的简单名字树
% Simple name tree with just some names 1 0 obj << /Names [ (Apple) (Orange) % 这些都是排好序的,从A到Z. (Name 1) 1 % 值可以是任何类型 (Name 2) /Value2 (Zebra) << /A /B >> ] >> endobj
Number trees
数字树类似于名称树,只不过它的键是整数而不是字符串,并且按升序排序。同时,叶(或根)节点中包含键/值对为数字键的值,而不是名字键的值。
Stream Objects(流对象)
PDF中的流是8位字节的任意序列,可以是无限长度的,并且可以压缩或编码。因此,它们是用于存储其他标准化格式(如XML语法、字体文件和图像数据)的大数据块的对象类型。
流对象由对象的数据表示,该数据由包含流的属性的字典前面的数据表示,称为流字典。使用单词流(后面跟着行结束标记)和尾流(前面是行尾标记)有助于从其字典中描述流数据,同时也使它区别于一个标准字典对象。流字典从不单独存在;它始终是流对象的一部分。
流字典总是包含至少一个键长度,该键表示从流后一行的开始到最后一个在结束流前面的行字符结尾之前的字节的字节数。换句话说,它是序列化成PDF文件的实际字节数。在压缩流的情况下,它是压缩字节数。虽然通常不提供,但原始的未压缩长度可以指定为DL键的值。(DL key意义不明)
流字典中最重要的键之一是过滤键,当原始数据还没有被包括到流中的时候,它可以指定对原始数据的压缩或编码(如果有)。使用FlateDecode过滤器压缩大型图像和嵌入式字体是很常见的,而FlateDecode过滤器使用的技术与ZIP文件格式所使用的无损COM-压缩技术相同。对于图像,两个最常见的过滤器是生成一个JPEG/JFIF兼容流的DCTDecode,以及生成一个JPEG 2000兼容流的JPXDe代码。其他过滤器可在ISO 32000-12008的表6中找到。示例1-8显示了PDF中的流对象可能是什么样子。
Example 1-8. 一个流的例子
<< /Type /XObject /Subtype /Image /Filter /FlateDecode /Length 496 /Height 32 /Width 32 >> stream % 496字节的平面编码数据在这里... endstream
Direct versus Indirect Objects(直接对象与间接对象)
现在您已经了解了对象的类型,了解这些对象可以直接或间接地在PDF中表示是很重要的。
直接对象是那些在从文件中读取对象时直接获得的“内联”对象。它们通常存在于字典键的值中、或者数组中的条目,并且对象类型是你到目前为止在所有示例中看到过的对象类型。
间接对象是指通过引用和PDF阅读器不得不间接跳转文件才能以找到实际的值的对象。为了验证哪个对象被引用,每个间接对象在每个PDF中都有一个唯一的ID,它表示为一个正数,和一个代数,这个代数总是一个非负数,通常是零(0)。这些数字既用于定义对象,也用于引用对象。
虽然代数最初打算用作跟踪PDF版本的方法,但是现代PDF系统几乎从不使用生成号,因此它们几乎总是为零。
要使用间接对象,首先必须使用ID和代数以及obj和endobj关键字来定义它,如例1-9所示。
Example 1-9. 完全由直接对象构成的间接对象
3 0 obj % 对象ID号为3, 代数为0 << /ProcSet [ /PDF /Text /ImageC /ImageI ] /Font << /F1 << /Type /Font /Subtype /Type1 /Name /F1 /BaseFont/Helvetica >> >> >> endobj 5 0 obj (an indirect string) endobj % 一个直接数字 4 0 obj 1234567890 endobj
当您引用一个间接对象时,可以使用它的ID、它的代数和字符R。例如,可以看到类似于示例1-10这样的东西,其中有两个间接对象(ID号为4和5)的参考文献。
Example 1-10. 一个引用其他间接对象的间接对象
3 0 obj % 对象ID号为3, 代数为0 << /ProcSet 5 0 R % 引用ID号为5,代数为0的直接对象 /Font <</F1 4 0 R >> % 引用ID号为4,代数为0的直接对象 >> endobj 4 0 obj % 对象ID号为4,代数为0 << /Type /Font /Subtype /Type1 /Name /F1 /BaseFont/Helvetica >> endobj 5 0 obj % 对象ID号为5,代数为0 [ /PDF /Text /ImageC /ImageI ] endobj
通过使用ID号和代数的组合,可以在给定的PDF中唯一地标识每个对象。使用PDF的交叉参考表功能,可以很容易地找到每个间接对象并按要求从参考书加载。
除非ISO 32000中另有说明,否则在使用对象时,它可以是任意类型的——但流除外,后者只能是间接的。
File Structure(文件结构)
如果要在PDF查看器中查看一个简单的PDF文件(我们称之为HelloWorld.pdf),它将如图1-1所示

图1-1.Hello World.pdf
但是,如果要在文本编辑应用程序中查看HelloWorld.pdf,它将类似于示例1-11。
Example 1-11.在文本编辑器中“HelloWorld d.pdf”是什么样子?
%PDF-1.4 %%EOF 6 0 obj << /Type /Catalog /Pages 5 0 R >> endobj 1 0 obj << /Type /Page /Parent 5 0 R /MediaBox [ 0 0 612 792 ] /Resources 3 0 R /Contents 2 0 R >> endobj 4 0 obj << /Type /Font /Subtype /Type1 /Name /F1 /BaseFont/Helvetica >> endobj 2 0 obj << /Length 53 >> stream BT /F1 24 Tf 1 0 0 1 260 600 Tm (Hello World)Tj ET endstream endobj 5 0 obj << /Type /Pages /Kids [ 1 0 R ] /Count 1 >> endobj 3 0 obj << /ProcSet[/PDF/Text] /Font <</F1 4 0 R >> >> endobj xref 0 7 0000000000 65535 f 0000000060 00000 n 0000000228 00000 n 0000000424 00000 n 0000000145 00000 n 0000000333 00000 n 0000000009 00000 n trailer << /Size 7 /Root 6 0 R >> startxref 488 %%EOF
看到上面的例子,您可能会得到错误的印象,即PDF文件是一个文本文件,可以使用文本编辑器进行常规编辑——不!PDF文件是一个结构化的8位二进制文档,由一系列基于8位字符的标记描述,由空格分隔,排列成(任意长的)行。这些标记不仅用于描述各种对象及其类型,正如您在上一节中所看到的,而且还可以定义PDF的四个逻辑部分开始和结束的位置。(见图1-2.)
如前所述,PDF中的标记总是以ASCII中的8位字节编码(并因此解码)。它们不能以任何其他方式进行编码,例如Unicode。当然,特定的数据或对象值可以用Unicode编码;我们将在出现这些情况时再讨论它们。
White-Space(空白)
表1-1中所示的空格字符在PDF中被用来分隔句法结构,例如名称和数字。
Table 1-1. 空白字符
| 十进制 | 十六进制 | 八进制 | 名字 |
| 0 | 00 | 000 | NULL(NUL) |
| 9 | 09 | 011 | HORIZONTAL TAB(HT) |
| 10 | 0A | 014 | LINE FEED(LF) |
| 12 | 0C | 014 | FORM FEED(FF) |
| 13 | 0D | 015 | CARRIAGE RETURN(CR) |
| 32 | 20 | 040 | SPACE(SP) |
在除注释、字符串、交叉引用表条目和流以外的所有上下文中,PDF将任何连续空格字符序列视为一个字符。
回车(0DH)和换行(0Ah)字符,也称为换行符,被视为一行的结尾标记(EOL)。一个回车紧接着一个换行的组合,只视作一个EOL标记来处理。EOL标记通常与任何其他空白字符相同。但是,有时需要一个EOL标记,出现在一行的开头标记之前。
PDF的四个部分
图1-2展示了PDF的四个部分:头部、预告、正文和交叉引用表。
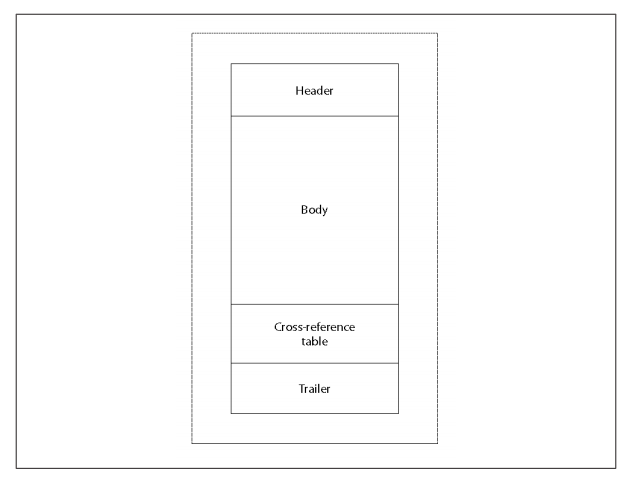
图1-2.PDF的四个部分
头部
PDF的头从文件的0字节开始,由至少8个字节组成,后面是行尾标记。这8个字节用于明确标识这个文件是一个PDF(%PDF-),并给出文件符合的标准版本号(例如,1.4)。如果您的PDF包含实际的二进制数据(最近几乎所有的数据都包含),那么接下来将有第二行,它也以PDF注释字符%(百分比符号)开始。在第二行的%之后,至少有四个ASCII值大于127的字符。尽管任何四个(或更多)值都很好,但最常用的值是âãÏÓ(0xE2E3CFD3)
第二行通过程序来简单地计算高阶ASCII值来判断是ASCII还是二进制。包含这些值确保PDF始终被视为二进制。
预告
在PDF的头部下面,你可以找到预告。示例1-12给出了一个简单的例子。预告主要是一个字典,它包含键和值,提供文档级别的信息,这些信息是处理文档本身所必需的。
Example 1-12. 一个简单的预告
trailer << /Size 23 /Root 5 0 R /ID[<E3FEB541622C4F35B45539A690880C71><E3FEB541622C4F35B45539A690880C71>] /Info 6 0 R >>
两个最重要的键,也是仅有的两个必须要有的键是Size和Root。Size键告诉我们在预告字典前面的交叉参考表中应该找到多少条目。Root键的值为文档的目录字典,您将从这里开始查找PDF中的所有对象。
预告中的其他常见键是加密的键,其存在可以快速识别出这个PDF已被加密。ID键,它为文档提供两个唯一的ID;以及Info键,它表示提供文档级元数据的原始方法(如第12章所述,已被替换)。
正文
正文是构成实际文档本身的所有九种类型的对象都位于的位置。您将在后面的“文档结构”中看到更多关于这一点的信息,同时查看各种对象以及它们是如何被组织的。
交叉引用表
交叉参考表的概念和实现比较简单,但它是PDF的核心属性之一。此表为文件中的每个间接对象提供了相对于文件开头的二进制偏移量,允许PDF处理器在任何时间快速查找并读取任何对象。这种随机访问模型意味着可以快速打开和处理PDF,而不必将整个文档加载到内存中。此外,无论页码中的“数字跳转”有多大,页面之间的导航都是快速的。在文件末尾使用交叉引用表还提供了两个额外的好处:在一次传递中创建PDF(不进行回溯)是可能的,以及能促进对文档的增量更新的支持。(示例见后面的“增量更新”)。
交叉引用表的原始表格(PDF1.0至1.4)由一个或多个交叉引用部分组成,其中每个部分都是一系列和对象的文件偏移量、代数、以及它是否在使用中有关的条目(每个对象一行)。最常见的表类型,如图1-3所示,只有一个部分列出所有对象。
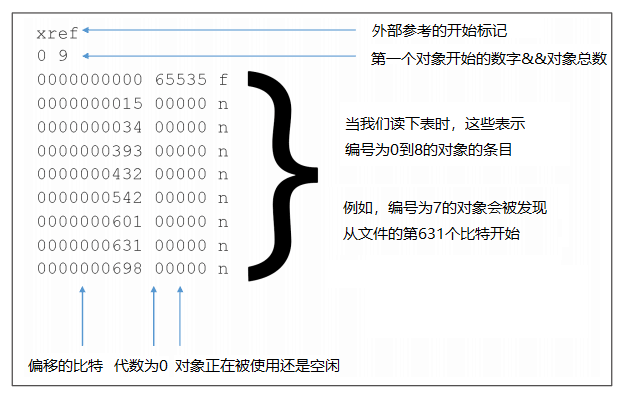
图1-3.经典交叉引用表
这种类型的交叉参考表遵循一种非常严格的格式,在这种格式中,列的位置是固定的,并且零是不可省略的。
您可能会注意到,交叉参考表每一行第二列中的数字的值总是为零,除了第一列的值为65535。该值与f一起,清楚地表明具有该ID的对象无效。由于PDF文件从来没有ID为0的对象,所以第一行始终与您在本例中看到的一样。
但是,当PDF包含增量更新时,您可能会看到类似于示例1-13中的交叉引用部分。
例1-13.更新的交叉引用部分
xref 0 1 0000000000 65535 f 4 1 0000000000 00001 f 6 2 0000014715 00000 n 0000018902 00000 n 10 1 0000019077 00000 n trailer <</Size 18/Root 9 0 R/Prev 14207 /ID[<86E7D6BF23F4475FB9DEED829A563FA7><507D41DDE6C24F52AC1EE1328E44ED26>]>>
随着PDF文档变得越来越大,很明显,拥有这种非常冗长(且不可压缩)的格式是一个需要解决的问题。因此,在PDF1.5中,引入了一种称为交叉引用流(因为数据作为标准流对象存储)的新类型的交叉引用存储系统。除了能够被压缩之外,新格式更加紧凑,支持大于10 GB的文件,同时还提供其他类型扩展的可能(尚未使用)。除了将交叉引用表改变为流之外,这个新系统还可以将间接对象的集合存储在另一种称为对象流的特殊流中。通过智能地将对象拆分到多个流中,可以优化PDF的加载时间和内存消耗。示例1-14显示了交叉引用流的样子。
例1-14.在交叉引用流中
stream 01 0E8A 0 % 对象2的条目 (0x0E8A = 3722) 02 0002 00 % 对象3的条目 (在对象流2中,索引为0) 02 0002 01 % 对象4的条目 (在对象流2中,索引为1) 02 0002 02 % . . . 02 0002 03 02 0002 04 02 0002 05 02 0002 06 02 0002 07 % 对象流10的条目 (在对象流2中,索引为7) 01 1323 0 % 对象流11的条目 (0x1323 = 4899) endstream
增量更新
如前所述,PDF的一个关键特性就是通过使用预告和文档末尾的交叉引用表实现的,这就是增量更新的概念。由于更改的对象被写入PDF的末尾,如图1-4所示,保存修改非常快速,因为不需要读取和处理每个对象。
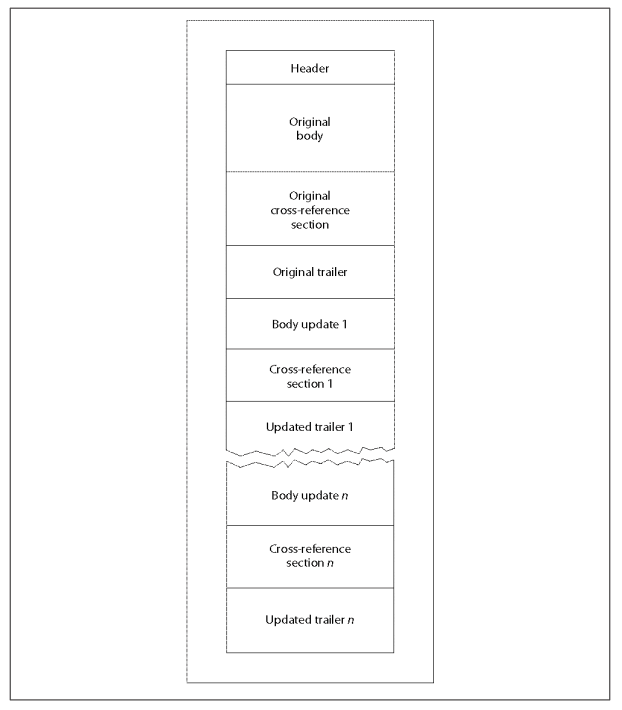
图1-4.包含增量更新部分的PDF布局
每个在初始数据后的交叉引用部分都通过预告字典中的Prev键返回到它之前的交叉引用(参见第16页的“拖车”),然后只列出新表中的新对象、已更改对象或已删除对象,如例1-13所示。
虽然查看器实际上不提供此功能(除了应用了后面“签名字段”中的数字签名之后),使用增量更新意味着可以跨保存边界支持多个撤消操作。然而,这也带来了危险,别人可能可以看到你之前的数据。即使您认为您从文件中删除了一些内容,但如果应用了增量更新而不是完全保存,它可能仍然存在。
在一个PDF中使用增量更新的时候,不要将经典的交叉引用与交叉引用流混为一谈是极其重要的。在原件中使用的任何类型的交叉引用都必须在更新部分中使用。如果将它们混合在一起,PDF阅读器可能会选择忽略更新。
Linearization(线性化)
正如您所看到的,在文件末尾使用交叉引用表具有各种优势。然而,也有一个很大的缺点,那就是PDF必须通过“流接口”(就像Web浏览器中的HTTP流)读取。在这种情况下,就算只想看其中的一页,一个普通的PDF也必须下载完整,这可能会造成不好的用户体验。
为了解决这个问题,PDF提供了一个叫做线性化的特性(ISO 32000-1:2008,附件F),但更多人称之为“快速网络视图”。
一个线性化文件与标准PDF文件有三种不同之处:
- 文件中的对象以一种特殊的方式排序,以便将特定页的所有对象组合在一起,然后按数字页码顺序组织(例如,第1页的对象,然后是第2页的对象,等等)。
- 在头部后面紧随着一个特殊的线性化参数字典,该字典将文件标识为线性化,并包含它所需要处理的各种信息。
- 在文件的开头放置部分交叉参考表和预告,以便访问根对象所需的所有对象,加上第一页要展示出来的那些对象。(通常是第一页)
当然,与标准PDF一样,对象仍然以相同的方式引用,继续通过交叉引用表对任何对象进行随机访问。如例1-15所示是线性化PDF的一个片段。
Example 1-15. 线性化PDF片段
%PDF-1.7 %%EOF 8 0 obj <</Linearized 1/L 7546/O 10/E 4079/N 1/T 7272/H [ 456 176]>> endobj xref 8 8 0000000016 00000 n 0000000632 00000 n 0000000800 00000 n 0000001092 00000 n 0000001127 00000 n 0000001318 00000 n 0000003966 00000 n 0000000456 00000 n trailer <</Size 16/Root 9 0 R/Info 7 0 R/ID[<568899E9010A45B5A30E98293 C6DCD1D><068A37E2007240EF9D346D00AD08F696>]/Prev 7264>> startxref 0 %%EOF % 正文对象从这里开始...
混合线性化和增量更新可能会产生意想不到的结果,因为使用线性化的交叉引用表将取代只存在于文件末尾的更新版本。因此,指定用于在线使用的文件应该被完全保存,以删除更新并确保正确的线性化表。
文件结构
现在您已经了解了PDF中的各种对象以及它们是如何组合在一起形成物理文件布局/结构的,现在是时候将它们放在一起形成一个实际的文档了。
目录字典
PDF文档是对象的集合,从根对象(Root)开始(图1-5)。之所以称其为根,是因为如果您将PDF中的对象看作树(或一个有向图),这个对象位于树/图的根处。从这个对象中,您可以找到处理PDF页面及其内容所需的所有其他对象。
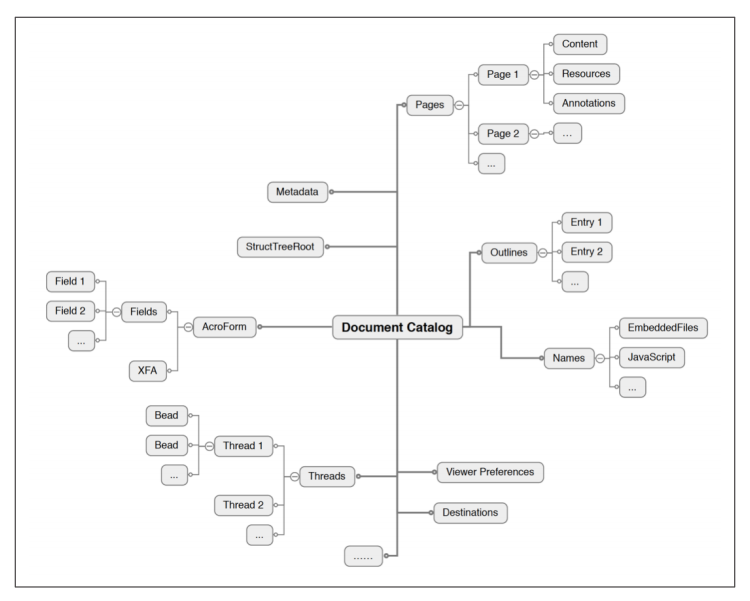
图1-5.PDF对象的类图结构
根始终是一个类型为目录的对象,并被称为文档的目录字典。它有两个必需的键:
- 类型,其值始终为名字对象目录
- 页,其值是对页面树的间接引用
虽然能够访问PDF的页面显然很重要,但也有二十多个可选键也可以出现(参见ISO32000-1:2008,表28)。这些代表文件级别的信息,包括:
• 基于XML的元数据(XML-based metadata)
• 打开操作 (OpenActions)
• 可填充形式 (Fillable forms)
• 可选内容(Optional content)
• 逻辑结构与标签(Logical structure and tags)
示例1-16显示了一个目录对象的示例。
Example 1-16.目录对象
<< /Type /Catalog /Pages 533 0 R /Metadata 537 0 R /PageLabels 531 0 R /OpenAction 540 0 R /AcroForm 541 0 R /Names 542 0 R /PageLayout /SinglePage /ViewerPreferences << /DisplayDocTitle true >> >>
让我们看看一些键(以及它们的值),您可能会发现在PDF中包含这些键是很有用的,以便改进用户体验:
页面控件(PageLayout)
页面控件键用于告诉PDF查看器应该如何显示PDF页面。它的值是一个名字对象。若要一次显示它们,请使用SinglePage这个值,或者如果您希望页面全部位于一个长的连续列中,则使用OneColumn值。还可以一次为两个页面指定值(有时称为spread),具体取决于您希望奇数页在的位置:TwoPageLeft和TwoPageRight。
页模式(PageMode)
除了只显示PDF页面内容外,您可能希望用户可以立即访问PDF的一些导航元素。例如,您可能希望书签或概述可见。页模式(PageMode)键的值是一个名字对象,它明确显示了哪些额外的元素应该被显示(如果有的话),例如使用大纲(UseOutlines)、使用缩略图(UseThumbs)或使用附件(UseAttachments)。
阅读器偏好(ViewerPreferences)
与前两个示例键的值是名字对象不同,阅读器偏好(ViewerPreferences)键的值是阅读器偏好字典(见ISO 32000-1:2008,12.2)。在查看器首选项字典中可用的许多键中,最重要的一个键(如果您向文档中添加元数据,如第12章所述)在前面的示例中有显示:显示文档标题(DisplayDocTitle)。如果该值为true,则PDF查看器将指示PDF查看器在窗口的标题栏中不显示文档的文件名,如图1-6所示,而是显示其真实标题,如图1-7所示。

图1-6.显示文件名的窗口标题栏

图1-7.窗口标题栏显示文档标题
(未完待续)
6p 不愧是你!