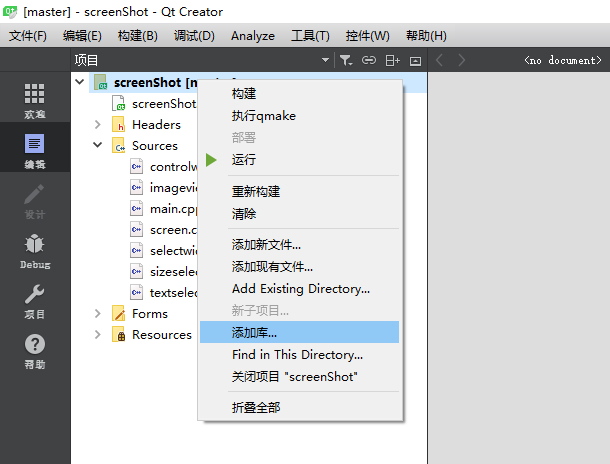
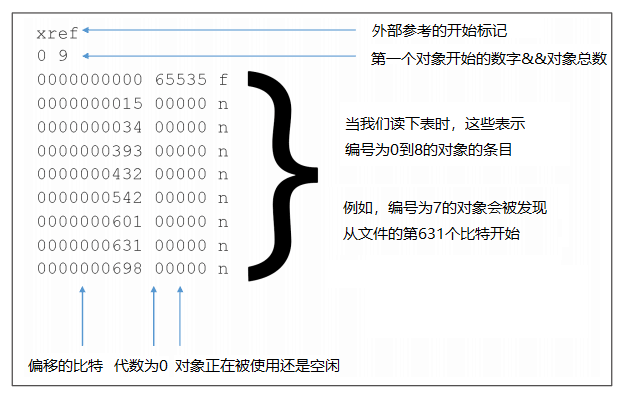
其中1-30题采用Python2.7,31-36题采用Python3.7
(1)有1、2、3、4四个数字,能组成哪些互不相同且无重复数字的三位数?
# -*- coding: utf-8 -*-
for i in range(1,5):
for j in range(1,5):
for k in range(1,5):
num = i*100+j*10+k;
if(i!=j & j!=k):
print num
(2)企业发放的奖金根据利润提成。利润(i)低于或等于10万元时,奖金可提10%;利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可提成7.5%;20万到40万之间时,高于20万元的部分,可提成5%;40万到60万之间时高于40万元的部分,可提成3%;60万到100万之间时,高于60万元的部分,可提成1.5%,高于100万元时,超过100万元的部分按1%提成,求当利润为i时应发放奖金总数。
# -*- coding: utf-8 -*-
num = input()
sum = 0
if(num <= 100000):
sum = sum + num * 0.1
if(num > 100000 & num <= 200000):
sum = sum + 100000 * 0.1 + (num-100000) * 0.075
if(num > 200000 & num <= 400000):
sum = sum + 100000 * 0.1 + 100000 * 0.075 + (num - 200000) * 0.05
if(num >400000 & num <= 600000):
sum = sum + 100000 * 0.1 + 100000 * 0.075 + 200000 * 0.05 + (num - 400000) * 0.03
if(num > 600000 & num <=1000000):
sum = sum + 100000 * 0.1 + 100000 * 0.075 + 200000 * 0.05 + 200000 * 0.03 + (num - 600000) * 0.015
if(num > 1000000):
sum = sum + 100000 * 0.1 + 100000 * 0.075 + 200000 * 0.05 + 200000 * 0.03 + 400000 * 0.015 + (num - 1000000) * 0.01
print sum
(3)输入某年某月某日,判断这一天是这一年的第几天?
# -*- coding: utf-8 -*-
def leapyear(year):
return ((year % 400 == 0) | (year % 4 == 0 & year % 100 != 0))
sum = 0
year = input("请输入年:")
month = input("请输入月:")
day = input("请输入日:")
if(month > 1):
sum = sum + 31
if(month > 2):
if(leapyear(year)):
sum = sum + 29
else:
sum = sum + 28
if(month > 3):
sum = sum + 31
if(month > 4):
sum = sum + 30
if(month > 5):
sum = sum + 31
if(month > 6):
sum = sum + 30
if(month > 7):
sum = sum + 31
if(month > 8):
sum = sum + 31
if(month > 9):
sum = sum + 30
if(month > 10):
sum = sum + 31
if(month > 11):
sum = sum + 30
sum = sum + day
print ("第%d天" %(sum))
(4)使用□■输出国际象棋棋盘(8*8)。
# -*- coding: utf-8 -*-
for i in range(1,9):
for j in range(1,9):
if((i+j)%2 == 0):
print("□"),
else:
print("■"),
print("")
(5)有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问第N个月的兔子总数为多少?
# -*- coding: utf-8 -*-
num = input()
a = 1
b = 1
def fun(num):
if(num == 1):
return 1
elif(num == 2):
return 1
else:
return fun(num - 1) + fun(num - 2)
print 2*fun(num)
(6)将一个正整数分解质因数。例如:输入90,打印出90=2*3*3*5。
# -*- coding: utf-8 -*-
num = input()
print(num),
print("="),
for i in range(2,num):
if(num == 1):
break;
while(num % i == 0):
print(i),
num = num / i;
if(num != 1):
print("*"),
(7)输入一个字符串,分别统计出其中英文字母、空格、数字和其它字符的个数。
# -*- coding: utf-8 -*-
str = raw_input()
alpha = 0
space = 0
number = 0
other = 0
for i in str:
if(i.isalpha()):
alpha=alpha + 1
elif(i.isdigit()):
number = number + 1
elif(i.isspace()):
space = space + 1
else:
other = other + 1
print("英文字母数=%d"%alpha)
print("数字数=%d"%number)
print("空格数=%d"%space)
print("其他字符数=%d"%other)
(8)输入a,n(0<a<10, 0<n<10),求s=a+aa+aaa+aaaa+aa…a(n个a)的值。例如a=2,n=5时为:2+22+222+2222+22222。
# -*- coding: utf-8 -*-
a = input()
n = input()
sum = 0
for i in range(n,0,-1):
sum = sum + i * a
a = a * 10
print sum
(9) 一球从100米高度自由落下,每次落地后反跳回原高度的一半;再落下,求它在第10次落地时,共经过多少米?第10次反弹多高?
# -*- coding: utf-8 -*-
num = 100.0
sum = 100.0
for i in range(0,9):
num = num / 2.0
sum = sum + num * 2.0
print ("第十次:%f"%(num/2.0))
print ("总距离:%f"%sum)
(10) 猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个。第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第10天早上想再吃时,见只剩下一个桃子了。求第一天共摘了多少?
# -*- coding: utf-8 -*-
num= 1
for i in range(0,9):
num= (num + 1)*2
print num
(11) 两个乒乓球队进行比赛,各出三人。甲队为a,b,c三人,乙队为x,y,z三人。已抽签决定比赛名单。有人向队员打听比赛的名单。a说他不和x比,c说他不和x,z比,请编程序找出三队赛手的名单。
# -*- coding: utf-8 -*-
def fun(num):
if num == 0:
return "X"
if num == 1:
return "Y"
if num == 2:
return "Z"
for i in range(0,3):
for j in range(0,3):
if(i != j):
for k in range(0,3):
if(i != k and j != k):
if(k != 0 and i != 0 and k != 2):
print "A vs",
print fun(i)
print "B vs",
print fun(j)
print "C vs",
print fun(k)
(12) 求1+2!+3!+…+20!的和。
# -*- coding: utf-8 -*-
def fun(num):
if(num == 1):
return 1
else:
return num * fun(num-1)
sum = 0
for i in range(1,21):
sum = sum + fun(i)
print sum
(13) 给一个不多于5位的正整数,要求:一、求它是几位数,二、逆序打印出各位数字。
# -*- coding: utf-8 -*-
def printConverse(num):
count = 0
while(num != 0):
temp = num % 10
print temp,
num = num/10
count = count + 1
return count
num = input()
print num,
print "逆序输出:",
a = printConverse(num)
print "位数为:",
print a
(14)有一分数序列:2/1,3/2,5/3,8/5,13/8,21/13…求出这个数列的前20项之和,用分数形式表现出来。
(1)使用fractions库函数实现
# -*- coding: utf-8 -*-
import fractions
from fractions import Fraction
a = 2
b = 1
sum = 0
for i in range(0,20):
sum = sum + Fraction(a,b)
temp = a
a = a + b
b = temp
print sum
(2)不用fractions库函数实现
# -*- coding: utf-8 -*-
a = 1
b = 2
denominator = 1
denominator = denominator * a * b
arrayDen = [1,2]
arrayNum = [2]
for i in range(0,18):
sum = a + b
arrayDen.append(sum)
a = b
b = sum
denominator = denominator * sum
arrayNum.append(sum)
arrayNum.append(a+b)
sumDen = denominator
sumNum = 0
for i in range(0,20):
sumNum = sumNum + sumDen/arrayDen[i]*arrayNum[i]
for i in range(0,20):
if(sumDen % arrayDen[i] == 0 and sumNum % arrayDen[i] == 0):
sumDen = sumDen / arrayDen[i]
sumNum = sumNum / arrayDen[i]
if(sumDen % (i+1) == 0 and sumNum % (i+1) ==0):
sumDen = sumDen/(i+1)
sumNum = sumNum/(i+1)
print sumNum,
print "/",
print sumDen
(15)求0—7所能组成的数字中,不重复的8位奇数的个数。
# -*- coding: utf-8 -*-
sum = 1
#从1,3,5,7中选择奇数作为末尾
sum = sum * 4
#选择非0首位
sum = sum * 7
for i in range(6,0,-1):
sum = sum * i
print sum
(16)已有结论“一个偶数总能表示为两个素数之和”,试输入一个偶数,用代码求出它对应的两个素数,若不止一组,尝试求相差最小的一组,比如16=13+3=11+5,则11+5更符合要求。
# -*- coding: utf-8 -*-
def isPrime(num):
for i in range(2,num):
if num % i == 0:
return False
return True
num = input()
temp = num / 2
for i in range(0,temp):
if( isPrime( temp + i ) and isPrime( temp - i )):
print temp+i,temp-i
break;
(17) 对一个列表元素进行排序,要求:非冒泡排序法,非内置排序函数。
# -*- coding: utf-8 -*-
array = [1,5,5,6,3,6,2,7,9,1,0]
def selectionSort(arr):
for i in range(0,len(arr)):
min = i;
for j in range(i+1,len(arr)):
if(arr[j] < arr[min]):
min = j
if i != min:
arr[min],arr[i] = arr[i],arr[min]
return arr
print selectionSort(array)
(18) 有一个已经排好序的列表。现输入一个数,要求按原来的规律将它插入数组中。(注意,并不知列表原来是什么顺序)
# -*- coding: utf-8 -*-
array = [9,5,3,2,1]
num = input()
def insertArray(array , num):
if(len(array) == 0 or len(array) == 1):
array.append(num)
else:
if(array[0] < array[len(array)-1]):
#升序
for i in range(0,len(array)-1):
if(num <= array[0]):
array.insert(0,num)
break
elif(num >= array[len(array)-1]):
array.append(num)
break
elif(array[i]<num and array[i+1]>=num):
array.insert(i+1,num)
else:
#降序
for i in range(0,len(array)-1):
if (num >= array[0]):
array.insert(0, num)
break
elif (num <= array[len(array) - 1]):
array.append(num)
break
elif (array[i] > num and array[i + 1] <= num):
array.insert(i + 1, num)
insertArray(array,num)
print array
(19) 一个列表逆序输出。(注意仅逆序输出,不要改变原列表元素)
# -*- coding: utf-8 -*-
array = [9,5,3,2,1]
for i in range(len(array)-1,-1,-1):
print array[i],
(20) 将一个整数依次按 十六进制、八进制、二进制输出。
# -*- coding: utf-8 -*- num = input() print hex(num) print oct(num) print bin(num)
(21) 写如下几个进制转换函数,实现八进制、十进制、十六进制字符串的互转,不能使用内建转换函数,dec2oct,dec2hex,oct2dec,oct2hex,hex2oct,hex2dec,比如hex2oct(“FF”)==dec2oct(“255”)==”377″。
略
(22)输入整数V和整数m,n(0<=m<n<=31,0是低位),取V的二进制的第m到n位数字。例如:输入52,二进制为:0011 0100,取第3到5位的结果为:011。
# -*- coding: utf-8 -*-
V = input()
m = input()
n = input()
a = str(bin(V))
print a
for i in range(m,n+1):
print a[len(a)-1-i],
(23) 输入一个列表,将列表中最大的数与第一个元素交换,最小的与最后一个元素交换,输出之。
# -*- coding: utf-8 -*-
array = [7,1,5,6,6,2,1,4,8,9,5]
max = 0
min = 0
for i in range(0,len(array)):
if(array[i] > array[max]):
max = i
if(array[i] < array[min]):
min = i
array[max],array[0] = array[0],array[max]
array[min],array[len(array)-1] = array[len(array)-1],array[min]
print array
(24) 有n个人围成一圈,顺序排号。从第一个人开始报数(从1到3报数),凡报到3的人退出圈子,问最后留下的是原来第几号的那位。
# -*- coding: utf-8 -*-
n = input()
array = []
count = 0
for i in range(1,n+1):
array.append(i)
while(len(array) > 1):
q = []
for i in array:
count = count + 1
if(count % 3 != 0):
q.append(i)
array = q
print array[0]
(25) 创建一个列表,依次输入整形元素并插入列表尾;
(1)反向输出之,
(2)输出其单数列的元素,再输出其双数列的元素
(3)让单数列元素按升序排列,双数列元素按降序排列
# -*- coding: utf-8 -*-
n = input()
array = []
for i in range(0,n):
temp = input()
array.append(temp)
for i in range(n-1,-1,-1):
print array[i],
print
for i in range(0,n):
if(i % 2 == 0):
print array[i],
print
for i in range(0,n):
if(i % 2 == 1):
print array[i],
print
for i in range(2,n,2):
for j in range(i+1,n,2):
if(array[j] > array[j-2]):
array[j],array[j-2] = array[j-2],array[j]
for i in range(1,n,2):
for j in range(i+1,n,2):
if(array[j] < array[j-2]):
array[j],array[j-2] = array[j-2],array[j]
print array
(26)创建一个字典,依次输入整形键、值并放入字典中。
1)依次打印键、值
2)以键的升序打印值
3)以值的升序打印键,同值则以键序
4)删除字典中键为1的元素,删除字典中值为1的元素
5)遍历字典,将字典中键为单数的元素都删去
# -*- coding: utf-8 -*-
dict = {}
a = []
b = []
for i in range(0,3):
a = input()
b = input()
dict[a]=b
for key in dict.keys():
print key,dict[key]
#以键排序
a = sorted(dict.items(),key = lambda e:e[0],reverse=False)
#以值排序
b = sorted(dict.items(),key = lambda e:e[1],reverse=False)
print a
print b
#删除字典中键为1的元素
for key in dict.keys():
if(key == 1):
dict.pop(1)
#删除字典中值为1的元素
for key in dict.keys():
if(dict[key] == 1):
dict.pop(key)
#普通遍历将字典中键为单数的元素都删去
count = 0
for key in dict.keys():
if(count % 2 == 0):
dict.pop(key)
count = count + 1
print dict
(27) 编写一个类CPeople,保存着人的姓名str、年龄int、性别bool、工号int;依次从键盘或者文件输入每个人的如上信息。
1)遍历输出所有人的信息,格式为:“姓名:xxx;年龄:xx;性别:男/女;工号:xxxxxx”
2)遍历输出所有男性/女性员工信息,注意列对齐
3)按年龄升序输出所有员工姓名,同年龄则以工号升序为序
4)存储people类对象的数据结构使用list/dict,重新实现上述需求
# -*- coding: utf-8 -*-
class CPeople(object):
def __init__(self , name , age , gender ,number):
self.name = name
self.age = age
self.gender = gender
self.number = number
liu = CPeople("liu",20,True,101)
chen = CPeople("chen",20,True,102)
deng = CPeople("deng",21,True,104)
yang = CPeople("yang",21,True,103)
tian = CPeople("tian",20,True,105)
xia = CPeople("xia",20,False,106)
arr = [liu,chen,yang,deng,tian,xia]
for i in arr:
print i.name,i.age,i.gender,i.number
#输出男性
print "BOY:"
for i in arr:
if(i.gender):
print i.name,i.age,i.gender,i.number
#输出女性
print "GIRL:"
for i in arr:
if(i.gender == False):
print i.name,i.age,i.gender,i.number
#按年龄升序输出所有员工姓名,同年龄则以工号升序为序
try:
import operator
except ImportError:
cmpfun = lambda CPeople:CPeople.age
else:
cmpfun = operator.attrgetter("age","number")
arr.sort(key = cmpfun , reverse = False)
for i in arr:
print i.name
(28) 某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下:
每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换。
写出其加密、解密函数。
# -*- coding: utf-8 -*-
data = 1007
#加密函数
def encryptionFun(num):
num1 = num/1000
num2 = num/100 % 10
num3 = num/10 %10
num4 = num % 10
num1 = (num1 + 5) % 10
num2 = (num2 + 5) % 10
num3 = (num3 + 5) % 10
num4 = (num4 + 5) % 10
num1,num4 = num4,num1
num2,num3 = num3,num2
return num1*1000+num2*100+num3*10+num4
#解密函数
def decodeFun(num):
num1 = num / 1000
num2 = num / 100 % 10
num3 = num / 10 % 10
num4 = num % 10
num1, num4 = num4, num1
num2, num3 = num3, num2
num1 = (num1 + 10 - 5)%10
num2 = (num2 + 10 - 5)%10
num3 = (num3 + 10 - 5)%10
num4 = (num4 + 10 - 5)%10
return num1*1000+num2*100+num3*10+num4
print encryptionFun(data)
print decodeFun(encryptionFun(data))
(29) 输入一个字符串,一个子串,计算字符串中子串出现的次数,已匹配过的字符不能再算做下一次匹配字符中。例如”abababab”, “abab” -> 2。
# -*- coding: utf-8 -*-
str= "abababab"
substr = "abab"
count = 0
i = 0
while(i <= len(str)-1):
if(str.find(substr, i, len(str) ) != -1):
count = count + 1
i = i + len(substr)
else:
i = i + 1
print count
(30) 输入一个字符串,出现频率最高的3个字。
# -*- coding: utf-8 -*-
text ="系统初始为Win7.64bit系统,每个项目有特定的操作系统环境需求,具体请咨询所属项目同事;如需调整默认启动系统,请在Win7系统下进行如下操作(必须在Win7系统下才能设置):计算机(右键)-属性-高级系统设置-高级-启动和故障恢复(设置)-默认操作系统"
dict = {}
for word in text:
if word not in dict:
dict[word] = 1
else:
dict[word] = dict[word] + 1
b = sorted(dict.items(),key = lambda e:e[1],reverse=True)
print(b)
(31) lst = [8,5,0,2,4,6,9,1,3,7],输入一个由0~9组成的列表,将其排序,要求lst位置靠前的元素,其排序后位置同样靠前。
# -*- coding: utf-8 -*-
lst = [8,5,0,2,4,6,9,1,3,7]
list = [0,1,2,3,4,5,6,7,8,9]
dict = {}
count = 0
for i in lst:
dict[i] = count
count = count + 1
for i in range(0,len(list)):
for j in range(1,len(list)):
if(dict[list[j]]<dict[list[j-1]]):
list[j],list[j-1] = list[j-1],list[j]
print (list)
(32)在键盘上,左手每隔2秒按下一个字母键,依次循环按下A-Z,右手每隔5秒按下一个数字键,依次循环按下0-9,写代码模拟求按下的第100个键,是那个手?按下的哪个键?
# -*- coding: utf-8 -*-
a = 'A'
b = '1'
count = 0
second = 0
press = ''
while(True):
if(second % 2 == 0):
press = a
a = chr(ord(a)+1)
count = count + 1
if(second % 5 == 0):
press = b
b = chr(ord(b)+1)
count = count + 1
second = second + 1
if(count == 100):
break
print(press,end="")
print("键")
if(press > 'A' and press < 'Z'):
print("左手")
else:
print("右手")
(33)有如下字典,记录每个地图场景能去往哪个地图场景
DATA = {
“中州城” : (“师道殿”, “云梦泽”, “逐风原”, “清水湾”, “千魂塔一层”, “帮派地图”, ),
“北漠城” : (“鸣沙洲”, “百花谷”, ),
“月牙湾” : (“云梦泽”, “伏波港”, ),
“伏波港” : (“月牙湾”, “百花谷”, ),
“鸣沙洲” : (“北漠城”, “苍茫山”, ),
“逐风原” : (“平安镇”, “中州城”, ),
“百花谷” : (“北漠城”, “伏波港”, ),
“千魂塔一层” : (“千魂塔二层”, “中州城”, ),
“云梦泽” : (“月牙湾”, “中州城”, ),
“苍茫山” : (“鸣沙洲”, ),
“清水湾” : (“中州城”, “平安镇”, ),
“师道殿” : (“绝情谷”, “真武门”, “蛮王殿”, “中州城”, “药王宗”, “天策府”, “拜火教”, “清虚观”, ),
“清虚观” : (“师道殿”, ),
“天策府” : (“师道殿”, ),
“真武门” : (“师道殿”, ),
“拜火教” : (“师道殿”, ),
“绝情谷” : (“师道殿”, ),
“蛮王殿” : (“师道殿”, ),
“药王宗” : (“师道殿”, ),
“千魂塔二层” : (“千魂塔一层”, ),
“平安镇” : (“清水湾”, “逐风原”, ),
“帮派地图” : (“中州城”, ),
}
写一个函数FindPath(source, target),返回一个list,元素为从source到target所经过的各个地图名的一条即可。
# -*- coding: utf-8 -*-
DATA = {
"中州城" : ("师道殿", "云梦泽", "逐风原", "清水湾", "千魂塔一层", "帮派地图", ),
"北漠城" : ("鸣沙洲", "百花谷", ),
"月牙湾" : ("云梦泽", "伏波港", ),
"伏波港" : ("月牙湾", "百花谷", ),
"鸣沙洲" : ("北漠城", "苍茫山", ),
"逐风原" : ("平安镇", "中州城", ),
"百花谷" : ("北漠城", "伏波港", ),
"千魂塔一层" : ("千魂塔二层", "中州城", ),
"云梦泽" : ("月牙湾", "中州城", ),
"苍茫山" : ("鸣沙洲", ),
"清水湾" : ("中州城", "平安镇", ),
"师道殿" : ("绝情谷", "真武门", "蛮王殿", "中州城", "药王宗", "天策府", "拜火教", "清虚观", ),
"清虚观" : ("师道殿", ),
"天策府" : ("师道殿", ),
"真武门" : ("师道殿", ),
"拜火教" : ("师道殿", ),
"绝情谷" : ("师道殿", ),
"蛮王殿" : ("师道殿", ),
"药王宗" : ("师道殿", ),
"千魂塔二层" : ("千魂塔一层", ),
"平安镇" : ("清水湾", "逐风原", ),
"帮派地图" : ("中州城", ),
}
lst = []
def FindPath(source ,target):
if(source == target):
return lst
elif(target in lst):
flag = True
return lst
for i in DATA[source]:
if(i in lst):
break
else:
lst.append(i)
if(target in FindPath(i,target)):
return lst
return lst
list = FindPath("平安镇","中州城")
print(list)
(34) 有如下字符串
s = “””师门任务20次,0,80
除魔任务20次,0,100
闹事妖怪10次,0,50
运镖任务5次,0,40
挖宝5次,0,40
角色升级1次,0,50
完成4次江湖悬赏令,10,40
任务链整百环3次,0,90
获得修炼经验400点,0,50
野外暗雷战斗60次,0,50″””
将如上字符串解析为如下格式,注意对齐方式,以及第一项“今天总计”并不出现在s中,而是各行数字计算值。
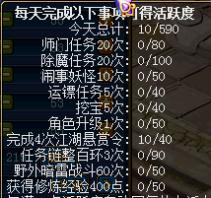
# -*- coding: utf-8 -*-
import re
s = """
师门任务20次,0,80
除魔任务20次,0,100
闹事妖怪10次,0,50
运镖任务5次,0,40
挖宝5次,0,40
角色升级1次,0,50
完成4次江湖悬赏令,10,40
任务链整百环3次,0,90
获得修炼经验400点,0,50
野外暗雷战斗60次,0,50"""
lst = (re.findall(r"\d+",s))
#计算总数
count = 0
sum1 = 0
lst1 = []
sum2 = 0
lst2 = []
for i in lst:
if (count % 3 == 1):
sum1 = sum1 + int(i)
lst1.append(i)
elif (count % 3 == 2):
sum2 = sum2 + int(i)
lst2.append(i)
count = count + 1
lst1.insert(0,str(sum1))
lst2.insert(0,str(sum2))
s1 = list(s)
count = 0
for i in range(0,len(s1)):
if(s1[i] is ","):
if(count % 2 == 0):
s1[i] = ":"
count = count + 1
else:
s1[i] = "/"
count = count + 1
s = ''.join(s1)
s1 = re.split("\n\t|:",s)
count = 0
res = []
res.append("今天总计:")
for i in range(0,len(s1)):
if(count % 2 == 0):
count = count + 1
else:
res.append(s1[i])
count = count + 1
print(" 每天完成以下事项可得活跃度")
tplt = "{0:{1}>10}"
for i in range(0,len(res)):
print(tplt.format(res[i],chr(12288)),end="")
print(":",end="")
print(lst1[i],end="")
print("/",end="")
print(lst2[i])
(35)举例说明python中可变类型与不可变类型都有哪些?
不可变类型:数字、字符串、元组
可变类型:列表、字典
(36)编写函数,检测给定的两维列表中是否有重复数据(已知该列表中保存的是正整数):check_data(lList),如果没有重复,则函数返回真。要求算法的时间复杂度不大于O(n)。
# -*- coding: utf-8 -*-
lst1 = [['apple','banana','orange'],
['rabbit','tiger','forg'],
['microsoft','apple','amazon'],
['intel','amd']]
def check_data(List):
map = {}
for i in List:
for j in i:
if(j not in map):
map[j] = 1
else:
return False
return True
print(check_data(lst1))