Form 2020.09.17
我突然想起了一个故事。
一个抱着一堆糖果的小孩。
一个拥有着很多糖果和好看衣服和好玩玩具的小孩。除此之外,它什么也没有。一个空洞的小孩。
EndlessNight

From 2020.09.16
在很远的群山中 有个地方
他们说那里是我家乡
家乡的意思就是像家一样
可我好久没有回去了 一直在流浪
很小的时候我讨厌那很小的地方
妄想着要逃离 背井离乡
我翻过了多少座山又越过海洋
还是没有逃出 思念的手掌
我不是故意让你哭泣的 姑娘
每个人心里本来有柔弱的地方
你若觉得难过 这故事我就不讲了
给你唱首歌吧 写的不是故乡
在我心里深处有一个姑娘
她也和你一样 头发不长
那时候我离开了那儿 离开了她
后来我再也没见过其他的她
她也和你一样 不爱穿裙子
她也和你一样 爱听我讲故事
她和你一样 是多愁善感的姑娘
可是你不是她 也不很像她
你不要再哭了 姑娘
脆弱的心灵 该怎么疗伤
把仅有的坚强 筑成一座墙
它可以保护你 少受点儿伤
如果实在想哭继续哭吧 姑娘
但是哭完了今天 明天还是一样



From 2020.09.13
别的风向都争先恐后来到,姗姗来迟的那一簇,是被丢下的。
大概这就是关键字,想表达或者受触动的,是孤零的落单情境?
这种事大概只有亲自体会过才有感受吧,说来也是好笑,我幼时虽怯懦,也还有好朋友,即使现在都陌生,那时却是真的不谙世事的好。及待受人排挤,愈发沉默孤寂,只喜欢在想象的世界里,别人常说我发呆,也不知在想什么。我不曾有过你那些乐观积极的心境,越长越大却越不爱说话,一切琐事家务我都默不作声的完成,作业如是,大抵做什么都如是。我和别人从来亲密不起来,太热情的碰触让我抗拒,往往朋友们走在前面,我落在最后,看着前面人的背影,不知道该表现出什么表情好。就好比读大学后,在友谊没发生变故之前,我也总是落在最后的那个。真的,我很认真的思考过这个问题,我该现出一种什么样的表情,才能让我看起来不那么孤寂,也不快乐,但我向来是面无表情,可能没人看得出分别吧。
以前还是很在意,很希望有人能和我并排走,在夕阳的余晖里说说笑笑。可惜盼得久了也不予期望了,顺便说一句,我现在没什么事都走得很快。也还自在。只是有点想法了。那晚来的风向,真是被丢下的吗?我觉得未必,有时的确是自以为孤凄,但其实有时候,我知道的确定的有时候,是自己故意慢悠悠的走的。觉得那朋友们自成融洽,虽也心向往之,但到底察觉和自己不是同类,故意的做出点分别来,也是有的。
虽然自己不想承认,红豆还是因为被大蛇丸抛弃而黯然,但最后却发现原来当年是自己做出的选择。那我们怎么能揣测那风向晚,是被丢下的呢?也许人家一开始是有点黯然,但没准走着走着,却自在起来逍遥起来了呢,呐,是吧。

From 2020.09.11
现在也希望有一天你们来删掉你们的故事,也希望你们有一天熬过黑暗,对过去释怀。
我知道这个世界上有着不可比拟的不幸,也希望……但是语言是无力又苍白的。
我什么都不能说,什么也做不了,我无法帮你缓解一点点痛苦。
我只是觉得我该留下点什么,起码你不是一个人,起码也有人曾经经历了你经历的,虽然你就是你一个人…语言果然太苍白无力。
我果然什么也说不了,甚至稍微给你安慰。
即便是想祈祷想祝福,也没有什么用处吧。
希望……希望有一天你熬过一切,然后所想像我现在所想的一样。
那就是最大的祝福了。

From 2020.09.06
对不起,要和很多人说声对不起,就算我这样,也还是被这个世界温柔以待。有曾经很多人对我好,就感觉这个世界都在温柔待我,所以就光是想想也要勇敢的活下去。因为曾经也是对好几个人来说都是最重要的存在,所以在现在也要勇敢的活下去。

From 2020.09.01
当我今日回归之时,看着还在痛苦中的你们,这只是我想对你们说的。其实你们不过是在经历别人经历过的人生,你们现在经历的痛苦,其实我或者是别的人也曾经历过,就这样带着这么多的阴暗痛苦决绝,我们大多数人还是最终没有把曾经的想法付诸实践,于是就这样拖拉着忍受着越熬越久,于是就一直活到了现在。
你会发现你的家庭很痛苦,你没有亲情。
没关系,然后之后你可能把希望和寄托放到友情身上。
没关系,因为你很快就会发现友情也并没有什么卵用。
没关系,因为再之后你可能接着遇到爱情,是不是久违的又有了知道爱的感觉了呢?
没关系,因为之后你就会看到爱情也会离你而去。
所以我想说什么呢?我就是想告诉你,比起你现在的悲剧,你还有很多悲剧没有经历哟,但是请往下看下去,其实这些并没有什么不好,因为当你被生活各方各面都打击过之后,你就能理解我现在此刻的心境了,你就能看透越来越多东西,也看淡越来越多东西,以前的我会为你们义愤填膺,但是现在的我不会了,我想让你们好好感受这深刻的痛苦,然而我知道我说的上句话并没有什么卵用,因为你们不过是曾经的我或是比曾经更惨的我,是我曾经的同僚的后继者,但是我想你们忍过来,在很久以后来体会我现在的心境。我想你们深刻记住你们现在过去还有未来的痛苦绝望黑暗,还有你们最初的善,我很同情你们,但也很无奈,悲剧总有人经历,而被选定的就是你们。
最初看火影的时候我最感到感同身受,鸣人,我爱罗,只爱自己的修罗,那种深刻的孤独,还有排挤、厌恶、憎恶、and仇恨,那些谩骂、and屈辱,那些一次又一次的崩溃,那些一次又一次的心痛…………..说到深处我却什么也说不出,我不知道用什么词来诉说,你们的那些又岂是用几个词能说出的,内心哽咽。真为你们心痛,但是希望你们尽可能好点的活过,但希望你们结局能像鸣人和我爱罗那样的好,原来历史真的是一直都在重蹈覆辙。

静态库和动态库最本质的区别就是:该库是否被编译进目标(程序)内部。
一般扩展名为(.a或.lib),这类的函数库通常扩展名为libxxx.a或xxx.lib 。
这类库在编译的时候会直接整合到目标程序中,所以利用静态函数库编译成的文件会比较大,这类函数库最大的优点就是编译成功的可执行文件可以独立运行,而不再需要向外部要求读取函数库的内容;但是从升级难易度来看明显没有优势,如果函数库更新,需要重新编译。
将自己设计的类导出为二进制形式的可执行代码。静态链接库有两种形式
动态函数库的扩展名一般为(.so或.dll),这类函数库通常名为libxxx.so或xxx.dll 。
与静态函数库被整个捕捉到程序中不同,动态函数库在编译的时候,在程序里只有一个“指向”的位置而已,也就是说当可执行文件需要使用到函数库的机制时,程序才会去读取函数库来使用;也就是说可执行文件无法单独运行。这样从产品功能升级角度方便升级,只要替换对应动态库即可,不必重新编译整个可执行文件。
从产品化的角度,发布的算法库或功能库尽量使动态库,这样方便更新和升级,不必重新编译整个可执行文件,只需新版本动态库替换掉旧动态库即可。
从函数库集成的角度,若要将发布的所有子库(不止一个)集成为一个动态库向外提供接口,那么就需要将所有子库编译为静态库,这样所有子库就可以全部编译进目标动态库中,由最终的一个集成库向外提供功能。
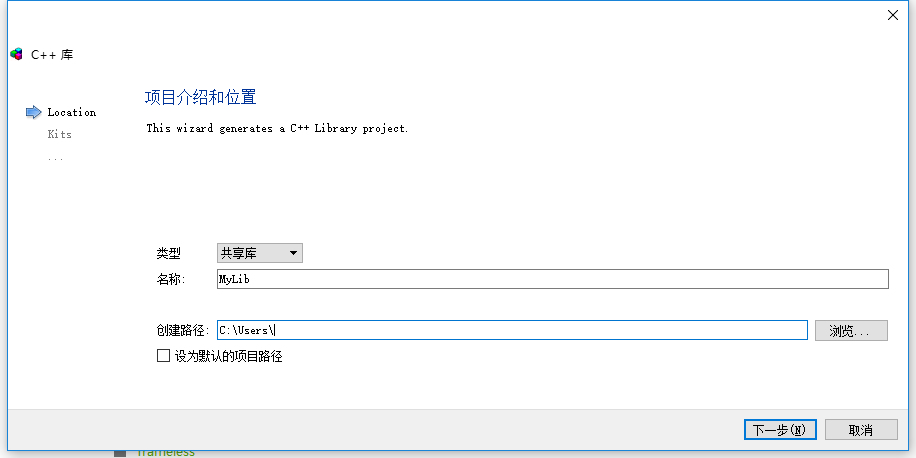
在QtCreator中按照如下步骤创建静态库,静态库名为MyLib。我们这里选用的构建套件为Desktop Qt 5.9.0 MinGW 32bit。

选择静态链接库,用来创建静态库。

创建好项目之后,我们会得到一个.pro文件,一个.cpp源文件,一个.h头文件,源文件和头文件中包含一个名为MyLib的类,我们这里简单使用,只给这个类的构造函数中添加一个弹窗“Hello World”。
//mylib.h
#ifndef MYLIB_H
#define MYLIB_H
#include <QMessageBox>
class MyLib
{
public:
MyLib();
};
#endif // MYLIB_H//mylib.cpp
#include "mylib.h"
MyLib::MyLib()
{
QMessageBox::information(NULL , "Title" , "Hello World");
}将该项目进行编译,生成两个文件:libMyLib.a和mylib.o,我们真正要用到的只需要libMyLib.a以及我们的MyLib.h头文件即可。
接下来我们创建一个UseLib的Qt Widgets Application项目来使用我们刚刚编译的静态库。
创建好UseLib项目后,我们把MyLib.h和MyLib.a放到UseLib项目源码文件夹中,并在UseLib.pro中加入如下代码用以包含我们的静态链接库:
//UseLib.pro
LIBS += \
$$PWD/libMyLib.a接下来我们将MyLib.h添加为UseLib项目的文件,并在mainwindow.h中include上MyLib.h。
接下来就可以在mainwindow.h和mainwindow.cpp中使用该静态链接库里的MyLib对象啦。
项目结构如下:
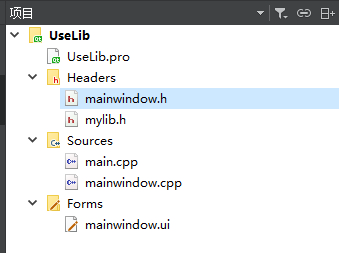
在mainwindow.cpp的MainWindow类的构造函数中我们加入如下代码:
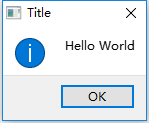
MyLib *lib = new MyLib();编译并运行,就可以看到在我们的UseLib项目的界面出来之前,就已经执行了我们静态库MyLib中的构造函数中的弹窗~调用静态库成功!
在QtCreator中按照如下步骤创建动态库,动态库名为MyLib。我们这里选用的构建套件为Desktop Qt 5.9.0 MinGW 32bit。
选择共享库,用来创建动态库。
创建好项目之后,我们会得到一个.pro文件,一个.cpp源文件,一个.h头文件,一个mylib_global.h头文件,源文件和头文件中包含一个名为MyLib的类,我们这里简单使用,只给这个类的构造函数中添加一个弹窗“Hello World”。
//mylib.h
#ifndef MYLIB_H
#define MYLIB_H
#include <QMessageBox>
class MyLib
{
public:
MyLib();
};
#endif // MYLIB_H//mylib.cpp
#include "mylib.h"
MyLib::MyLib()
{
QMessageBox::information(NULL , "dll title" , "Hello World");
}将该项目进行编译,生成三个文件:libMyLib.a、MyLib.dll和mylib.o,我们真正要用到的只需要MyLib.dll以及我们的MyLib.h头文件即可。
接下来我们创建一个UseLib的Qt Widgets Application项目来使用我们刚刚编译的静态库。
创建好UseLib项目后,我们把MyLib.h和MyLib.dll放到UseLib项目源码文件夹中,并在UseLib.pro中加入如下代码用以包含我们的动态链接库:
//UseLib.pro
LIBS += -L$$PWD -lMyLib接下来我们将MyLib.h添加为UseLib项目的文件,并在mainwindow.h中include上MyLib.h。
接下来就可以在mainwindow.h和mainwindow.cpp中使用该动态链接库里的MyLib对象啦。
项目结构如下:
在mainwindow.cpp的MainWindow类的构造函数中我们加入如下代码:
MyLib *lib = new MyLib();编译并运行,就可以看到在我们的UseLib项目的界面出来之前,就已经执行了我们动态库MyLib中的构造函数中的弹窗~调用动态库成功!

需要注意的是,如果要将应用程序发布,需要将动态链接库跟随主程序一起发布。
当你的应用程序使用了第三方的动态库,或自己开发的动态库的时候,使用macdeployqt则会报错:
ERROR: no file at "/usr/lib/libXXXX.1.dylib"用otool -L untitled.app/Contents/MacOS/untitled 可以看到输出中包含如下这一行。
libXXXX.1.dylib (compatibility version 1.0.0, current version 1.0.1)这一行表示你的应用程序找这个动态库是相对路径的,即要求你的这个动态库在/usr/lib目录下或/usr/local/lib目录下。你双击编译出的用用程序提示无法打开,点击报告会显示为找不到库。其实是在/usr/lib目录下或/usr/local/lib目录下 找不到这个库。你手工放置库文件到这个目录即可双击运行。注意:你没有权限把库放到/usr/lib下,因此你放到/usr/local/lib即可。
注意在你动态库的xxx.pro文件中加入如下的配置。否则,双击应用程序的时候会到/usr/lib找,而不是在/usr/local/lib找。
unix {
target.path = /usr/local/lib
INSTALLS += target
}为了发布出去的应用程序不再在/usr/local/lib目录下找对应的动态库。而是在bundle包(目录)中查找。从而用户复制你的bundle到“应用程序”目录即可直接运行。因此你需要修改应用程序记录动态库的路径。修改方法如下:
install_name_tool -change "libXXXX.1.dylib" "@rpath/xxxx/libXXXX.1.dylib" untitled.app/Contents/MacOS/untitled 命令表示,把bundle包里面的应用程序untitled储存的此库的路径从”libXXXX.1.dylib”改为”@rpath/xxxx/libXXXX.1.dylib”。
执行完此命令后,找到untitled这个编译好的程序右键“打开包内容/Show Package Contents”,然后跳转到bundle的包内部目录里面,切换到“Contents”目录下的Frameworks目录中,然后创建一个目录“xxxx”(自己起的名字)然后把你制作的动态库或第三方的动态库放到这个目录。保证库的名字和”@rpath/xxxx/libXXXX.1.dylib”写的库的名字对应上。
以上就都做好了,现在用otool工具检测一下应用程序untitled包含库的路径:
otool -L untitled.app/Contents/MacOS/untitled就会变成以@rpath开头的相对路径了。这次你双击“untitled”程序,程序就不会报错说找不到库了。
然后执行以下命令打包为dmg安装包。
macdeployqt ./build-untitled-Desktop_Qt_5_12_3_clang_64bit-Release/untitled.app -dmg为何redis中大量使用的是SDS,而不是传统的C语言字符串表示法存储字符串?到底什么是SDS?为什么要使用SDS?其相对于传统的C语言字符串有何优点?本文会针对以上几点做一个详细的分析,帮助大家以及自己更好的理解redis中的简单动态字符串。
介绍SDS之前先简单介绍一下C语言中的传统字符串表示法
始终以空字符结尾的字符数组,c语言为其封装了大量的函数库操作API
那么基于以上特点,C字符串是否能够满足我们Redis高效,安全的需求呢?显然是不能的,单是一个获取字符串长度就需要遍历整个字符串数组了,必须重新定义一种新的结构以支持Redis中对于频繁高效操作字符串的要求。
基于以上C字符串的缺陷,Redis自己构建了一种名为简单动态字符串的抽象类型,简称SDS。
struct sdshdr {
// buf数组已经使用字节数量,即SDS字符串长度
int len;
// 记录buf数组中未使用字节的数量
int free;
// 字节数组,用于保存二进制数据
char buf[];
}
可以看出,SDS定义的结构中,增加了一个int类型的len属性用于记录SDS所保存的字符串长度,一个free属性用于记录数组中未使用的字节数量。
Redis中利用SDS字符串的len属性可以直接获取到所保存的字符串的长
度,直接将获取字符串长度所需的复杂度从C字符串的O(N)降低到了O(1)。
基于前面介绍的C字符串的特性,我们知道对于一个包含了N个字符的C字符串来说,其底层实现总是N+1个字符长的数组(额外一个空字符结尾),那么如果这个时候需要对字符串进行修改,程序就需要提前对这个C字符串数组进行一次内存重分配(可能是扩展或者释放),而内存重分配就意味着是一个耗时的操作。
Redis巧妙的使用了SDS避免了C字符串的缺陷,在SDS中,buf数组的长度不一定就是字符串的字符数量加一,buf数组里面可以包含未使用的字节,而这些未使用的字节由free属性记录。
SDS采用了空间预分配策略避免C字符串每一次修改时都需要进行内存重分配的耗时操作,将内存重分配从原来的每修改N次就分配N次降低到了修改N次最多分配N次。
首先检查SDS未使用空间即free属性是否够用,如果够用,则会直接使用未使用空间,而无须进行内存重分配。
空间预分配
所谓预分配就是额外多分配一部分空间给SDS,并不是仅仅只分配刚好够字符串扩展修改后的空间。
分配策略:
针对SDS字符串的缩短场景,SDS并不会立即释放多余出来的内存空间,而是将这部分内存空间记录再其free属性中,当SDS字符串进行扩展时,这部分未使用的内存空间就能直接用,而不需要进行内存重分配,这就是SDS的惰性空间释放。
在C字符串的拼接操作过程中,例如某程序员操作S1拼接S2,由于程序员忘记了给需要拼接的字符串S1分配足够的内存空间(到底需要分配多少内存呢?哈哈,当然需要遍历S2的字符数组才能知道S2的长度是多少,因为C字符串不记录自身的长度),那么拼接的时候就会导致缓冲区溢出的可能性。
针对以上情况,SDS的空间分配策略可以完全杜绝这种情况,因为当SDS 的API对SDS进行修改时,API会首先检查SDS的未使用空间是否足够,不够的化会进行内存重分配以扩展空间至足够修改所需的大小,然后再执行实际的修改操作,这样就可以达到杜绝缓冲区溢出的可能。
由于C字符串中保存的字符必须符合某种编码格式(如ASCII),这就限制了C字符串只能保存文本数据,而不能保存箱视频,音频,压缩文件这种的二进制数据。
另一个限制是C字符串中间不能包含空字符,否则中间的空字符会被认为是整个字符串的结尾,而导致后面的部分字符被忽略掉。
SDS的API被设计成了二进制安全的,以处理二进制的方式来处理SDS中存放再buf数组中的数据,原样存取,这就是为什么在SDS的结构中采用的是字节数组,而不是C字符串中的字符数组。
这样的二进制安全的SDS,使得Redis不仅可以保存文本,还可以保存任意格式的二进制数据。
由于C字符串本身具有大量操作API,SDS如果可以利用一部分C字符串的API那样就不用重复发明轮子了,所以Redis中的SDS遵循C字符串以空字符结尾的惯例,在SDS的API中,总会将SDS保存的数据末尾设置未空字符,在分配buf数组时也总会多分配一个字节来保存这个空字符,这样SDS就可以重用一部分C字符串库的API。
| 对比点 | C字符串 | SDS |
|---|---|---|
| 获取字符串长度时间复杂度 | O(N) | O(1) |
| API安全性 | 不安全,可能造成缓冲区溢出 | 安全,不会造成溢出 |
| 字符串修改N次需要几次内存重分配 | N次 | 至多N次 |
| 能够保存数据类型 | 只能保存文本 | 文本或二进制 |
| 对于C语言中字符串API的使用范围 | 所有 | 一部分 |
Redis中采用SDS替代C语言中传统字符串表示法,提升了获取字符串长度的效率,扩大了能够保存数据的类型范围,以及降低了每次修改字符串时候的内存重分配次数,甚至规避了在操作C字符串中可能出现的缓冲区内存溢出的可能性,从而为Redis中字符串操作的安全,高效提供了保障。
(1)读取 http body 部分
(2)根据 boundary 分析出分隔符特征(这个串是唯一的,不会与body内其他数据冲突)
(3)根据实际分隔符分段获取 body 内容
(4)遍历分段内容
(5)根据 Content-Disposition 特征获取其中值
(6)根据值中 filename 或 name 区分是否是包含二进制流还是表单数据的 k-v
(7)根据 filename 获取原始文件名
(8)从连续 两个 newline 字符串为起始至当前分段完毕,按照二进制流读取上传文件流信息。
完成后即有——
然后该干嘛干嘛,比如写文件到磁盘等。
具体怎么处理是服务器做的事儿,HTTP协议本身并没有死规定,以下说的只是解决问题的某一种思路。
有一个基本认识是,每一个请求都是一个流。而每一个用于传输文件的HTTP报文,都会有类似于这样的报头:
Content-Type: multipart/form-data; boundary=巴拉巴拉如果报头定义了这样的东西,就可以判断客户端采用了multipart格式传递信息,同时我们也拿到了boundray。
再考虑文件如何处理。以问题中提到的报文为例,payload(你题干中的报文格式并不对,我根据题目意思做了相应修改)为:
-----------------------------14579331036932498511351460782
Content-Disposition: form-data; name="userfile1"; filename="å¤æ³¨è¯´æ.txt"
Content-Type: text/plain
1.±ê×¢ÒÔiPhone6s ÆÁÄ»³ß´çΪ±ê×¼£»
2.Èç¹ûÐèÒª²»Í¬³ß´çµÄicon£¬ÔÙ¸øÎÒ˵¡£
-----------------------------14579331036932498511351460782
Content-Disposition: form-data; name="hehe"
tewtw
-----------------------------14579331036932498511351460782--1. 第一次读到定义的边界”—————————–14579331036932498511351460782″
意味着一个字段的开始;
2. 继续读入一行,发现这是个文件;再读入一行,发现定义了Content-Type,也许还会定义charset之类的信息;再读入一行发现是个 CRLF ,意味着后续的内容是文件数据,这时候可以构造一个新的临时文件对象,将后续的数据pipe到这个临时文件对象中。
3. 再一次读到边界”—————————–14579331036932498511351460782″意味着这一个字段结束,这时候可以去关闭刚刚创建的临时文件。
4. 然后开始继续下一字段解析过程。
ps:以上部分只是简单的说了解决思路,并不涉及检查、转换等工作。比如在流的pipe过程中,可能需要根据之前定义的charset进行流的转换,甚至如果发现Content-Type不是自己需要的,就压根不存而是直接pipe到黑洞中去。
编译环境:VS2019 + Win10 + cmake-gui-3.8.0 + cef_binary_3.2623.1401.gb90a3be_windows32
最后一个兼容Windows XP的CEF(2623)的下载地址:https://pan.baidu.com/s/1UoWt8Ffs_YPBCmYlHbipLg
提取码:x7ym
1、解压 cef_binary_3.2623.1401.gb90a3be_windows32 后,目录如下:

2、下载cmake-gui
下载地址:https://pan.baidu.com/s/1KdOaZXWX9gy7yVKVbJdpgA
提取码:ptnu
下载好cmake-gui并安装好之后打开cmake-gui.exe,设置如下:
Where is the source code : cef_binary_3.2623.1401.gb90a3be_windows32解压后的路径
where to build the binaries : cef_binary_3.2623.1401.gb90a3be_windows32解压后的路径
Configure: 选择你电脑上装有的VS的编译器的版本,如果选择了电脑本地并没有的VS编译器版本,会遇到如下情况:


用cmake生成编译工程时候报这样的错误,原因是配置错误导致cmake找不到对应的编译器,于是通过File->Delete cache清理配置,重新通过Configure更换你电脑上装有的VS的编译器的版本即可。
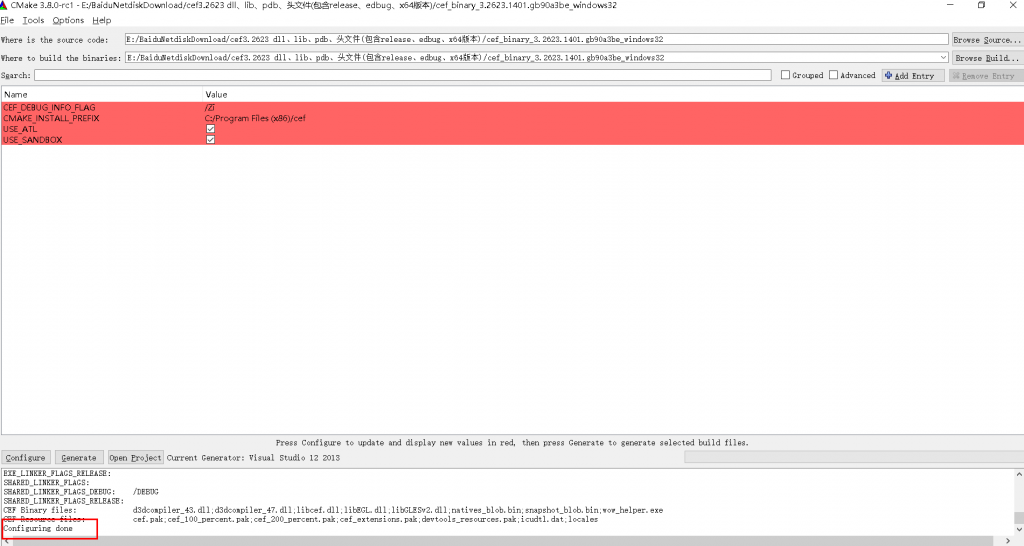
当出现Configuring done的时候点击Generate按钮即可生成对应版本的VS sln解决方案,使用VS打开生成解决方案即可。
VS2015打开cef.sln然后直接编译即可生成libcef_dll_wrapper.lib文件了,如下图项目cefsimple项目和cefclient项目会失败,这个并不影响生成我需要的libcef_dll_wrapper.lib,我就不解决了。

在这里还有一个坑就是这个工具最多只支持到VS2017,由于我的电脑上装了VS2013和VS2019,于是我选择了VS2013的配置并成功编译出了libcef_dll_warpper.lib,但在导入CEF浏览器实际项目调用的时候报了如下错误:error LNK2038: 检测到“_MSC_VER”的不匹配项问题。
_MSC_VER这个相当于做了宏的检测 _MSC_VER 定义编译器的版本。下面是一些编译器版本的_MSC_VER值:
MS VC++ 14.0 _MSC_VER = 1900 vs2015
MS VC++ 12.0 _MSC_VER = 1800 vs2013的编译器他的平台是v120
MS VC++ 11.0 _MSC_VER = 1700 vs2012的编译器他的平台是v110
MS VC++ 10.0 _MSC_VER = 1600 Visual C++ 2010
MS VC++ 9.0 _MSC_VER = 1500 Visual C++ 2008
MS VC++ 8.0 _MSC_VER = 1400 Visual C++ 2005
MS VC++ 7.1 _MSC_VER = 1310
MS VC++ 7.0 _MSC_VER = 1300
MS VC++ 6.0 _MSC_VER = 1200
MS VC++ 5.0 _MSC_VER = 1100
error LNK2038: 检测到“_MSC_VER”的不匹配项: 值“1800”不匹配值“1700”(main.obj 中)
原因:由于你使用了vs2012,工作集选择了更高的1800也就是vs2013的,致使msvc不兼容!
方法:在项目(解决方案资源管理器或者属性管理器里都行)右键属性-配置属性-常规中,平台工具集选用为合适平台即可,比如上面的就是要选择成2012的 v11版本,注意光选了还没有用,还要应用。
注意一个工程里面会有几个解决方案的时候,需要给每个解决方案都更改一遍,最后重新编译即可。